Introduction
Your legacy system is probably doing two jobs at once.
- It runs the business.
- It absorbs every shortcut the business has ever taken.
Modernization fails when teams treat it like a clean engineering project. It is not. It is a risk management project with code attached.
This guide is for teams planning a legacy modernization strategy that keeps revenue stable while you move from monolith to microservices, or at least to a modular monolith that can evolve.
You will see:
- When an incremental rewrite beats a big bang rewrite
- A refactor vs rewrite decision framework you can use in a workshop
- Data migration strategies that do not corrupt reporting
- Zero downtime patterns that keep customers out of your incident channel
Insight: If you cannot describe your cutover plan in one page, you do not have a cutover plan. You have hope.
In our delivery work across 360+ shipped projects, the teams that finish modernization are not the teams with the fanciest target architecture. They are the teams that keep scope small, measure reliability every week, and treat migrations like production incidents waiting to happen.
What we mean by modernization
Modernization is not only rewriting code. It is improving change speed and operational safety.
Typical outcomes that matter:
- Fewer production incidents per deploy
- Faster lead time from ticket to production
- Lower cost per transaction
- Better auditability for compliance by design
You can hit those outcomes with:
- Strangler fig approach and incremental modernization
- Targeted refactors around seams
- Selective rewrites for the parts that block progress
- Data and reliability work that makes changes safer
_> Modernization proof points
What we optimize for in delivery work
The failure modes to plan for
Most modernization projects do not fail because the new code is bad. They fail because the business cannot tolerate the transition period.
Common failure modes:
- Dual running costs explode. Two systems, two sets of bugs.
- Data gets out of sync. Finance loses trust in reports.
- Teams ship slower. Everyone is waiting on migration work.
- Reliability drops. Customers become your monitoring tool.
- The rewrite never finishes. You end up with a half built platform.
Key Stat: Many teams underestimate migration work by 2x to 5x. Treat that as a planning assumption until your own metrics prove otherwise.
A quick baseline checklist
Before you touch architecture, baseline what you have.
Capture these in a shared doc:
- Top 10 user journeys and their current latency and error rate
- Peak traffic windows and seasonal spikes
- Current deploy frequency and rollback rate
- Known data sources of truth and where they drift
- Compliance constraints: retention, audit logs, access controls
If you cannot measure it today, write it down as a gap and add instrumentation first.
Migration roadmap template
A simple plan that survives contact with productionKeep the roadmap short and measurable. Each phase should end with a shippable outcome.
Baseline and instrumentation
- Define SLOs for top journeys
- Add tracing and correlation ids
- Inventory data sources of truth
Seams and routing
- Add facade or gateway
- Implement feature flags and routing rules
- Choose first thin slice
First slice extraction
- Build new component behind the seam
- Shadow traffic and compare outputs
- Canary rollout with abort rules
Data migration per domain
- Pick strategy: backfill, dual writes, CDC
- Build validation dataset and reconciliation reports
- Dry runs with production like volume
Cutover and decommission
- One page cutover plan
- Final traffic shift
- Delete legacy paths and reduce infra cost
Add dates only after you have phase 1 metrics. Until then, use capacity based planning.
Incremental modernization toolkit
_> Small controls that reduce risk fast
Facade and routing layer
Creates seams so you can move one workflow at a time without breaking clients.
Validation datasets
A curated set of tricky records and edge cases to rerun on every migration build.
Canary with abort rules
Gradual rollout with automatic rollback when KPIs cross thresholds.
Backward compatible schemas
Schema changes that support old and new code paths during the transition.
Idempotency keys
Makes retries safe during dual writes, queue replays, and partial failures.
Reconciliation reports
Business level checks that catch silent data bugs before finance does.
Strangler fig and incremental modernization
The strangler fig approach is the most reliable path when the system must keep running. You wrap the legacy system, route a small slice of traffic to a new component, then expand.
It is also the cleanest way to do an incremental rewrite without betting the company on a date.
A practical strangler fig plan:
- Create seams. Put an API gateway or facade in front of the monolith.
- Pick one thin slice. One endpoint, one workflow, one report.
- Mirror and compare. Run the new path in shadow mode, compare outputs.
- Gradual cutover. Route 1%, then 10%, then 50%, then 100%.
- Delete legacy code. If you do not delete, you are only adding cost.
Insight: The strangler fig approach fails when teams skip step 5. Keeping both paths forever is not safety. It is permanent complexity.
Monolith to microservices, without the hype
Going from monolith to microservices can help, but only if you can operate it.
Microservices add:
- More deploy units
- More network failure modes
- More observability requirements
- More ownership boundaries
A safer intermediate target is often:
- A modular monolith with clear boundaries
- One or two extracted services where scaling or ownership is truly blocked
Use microservices where they buy you something measurable, like isolated scaling for a high traffic workflow or independent compliance boundaries.
Incremental modernization patterns that work
Patterns we see working in production:
- Facade first: stable API in front of unstable internals
- Anti corruption layer: translate legacy models into clean domain objects
- Branch by abstraction: switch implementations behind an interface
- Shadow reads: read from new store, but trust old store until proven
Patterns that often backfire:
- Extracting services before you have logging, tracing, and alerts
- Migrating data before you know your data quality issues
- Building a perfect target platform before shipping any user value
Rewrite vs refactor decision tree
Run it in a workshopAnswer each question with evidence.
Do we have existential platform constraints?
- Yes: incremental rewrite with strict cutover plan
- No: go to 2
Can we create seams without breaking critical flows?
- No: refactor toward modularization
- Yes: go to 3
Do we have tests and observability for the slice?
- No: invest in testability and monitoring first
- Yes: go to 4
Is the domain changing significantly in the next 12 months?
- Yes: incremental rewrite for that slice
- No: refactor in place
If you end up with “big bang rewrite,” write down why rollback is still possible. If you cannot, revisit the decision.
Refactor vs rewrite decision framework
This is where teams burn months arguing.
Data Cutover Checklist
Correctness beats speedData is where migrations get expensive, especially when bugs are silent (wrong invoices, wrong permissions, missing events days later). Answer these before you move traffic:
- Source of truth today: verify in production behavior, not docs.
- Validation: go beyond row counts. Compare aggregates, invariants, and sampled business cases (for example: invoice totals per customer per month).
- Rollback plan: define what you can revert and what you cannot (schema changes, external side effects).
A workable timeline often looks like: backfill → dual writes → dual reads → validation gates → gradual traffic shift → legacy write freeze → final cutover → decommission. Measure mismatch rate and time to detect, not just completion.
A rewrite is tempting because it feels clean. A refactor feels slow because it keeps the mess visible.
The right answer is usually mixed. Rewrite the parts that block progress. Refactor the parts that can be improved safely in place.
Comparison table
| Dimension | Refactor in place | Incremental rewrite | Big bang rewrite |
|---|---|---|---|
| Business risk | Lower | Medium | High |
| Time to first value | Weeks | Weeks to months | Months to years |
| Parallel run cost | Low | Medium | High |
| Data migration complexity | Lower | Medium | High |
| Talent requirements | Medium | High | High |
| Best for | Stable domains, clear tests | High change areas, known seams | Rare cases with hard platform limits |
Insight: If you cannot run the old and new systems side by side, you are not choosing a rewrite. You are choosing a cutover event.
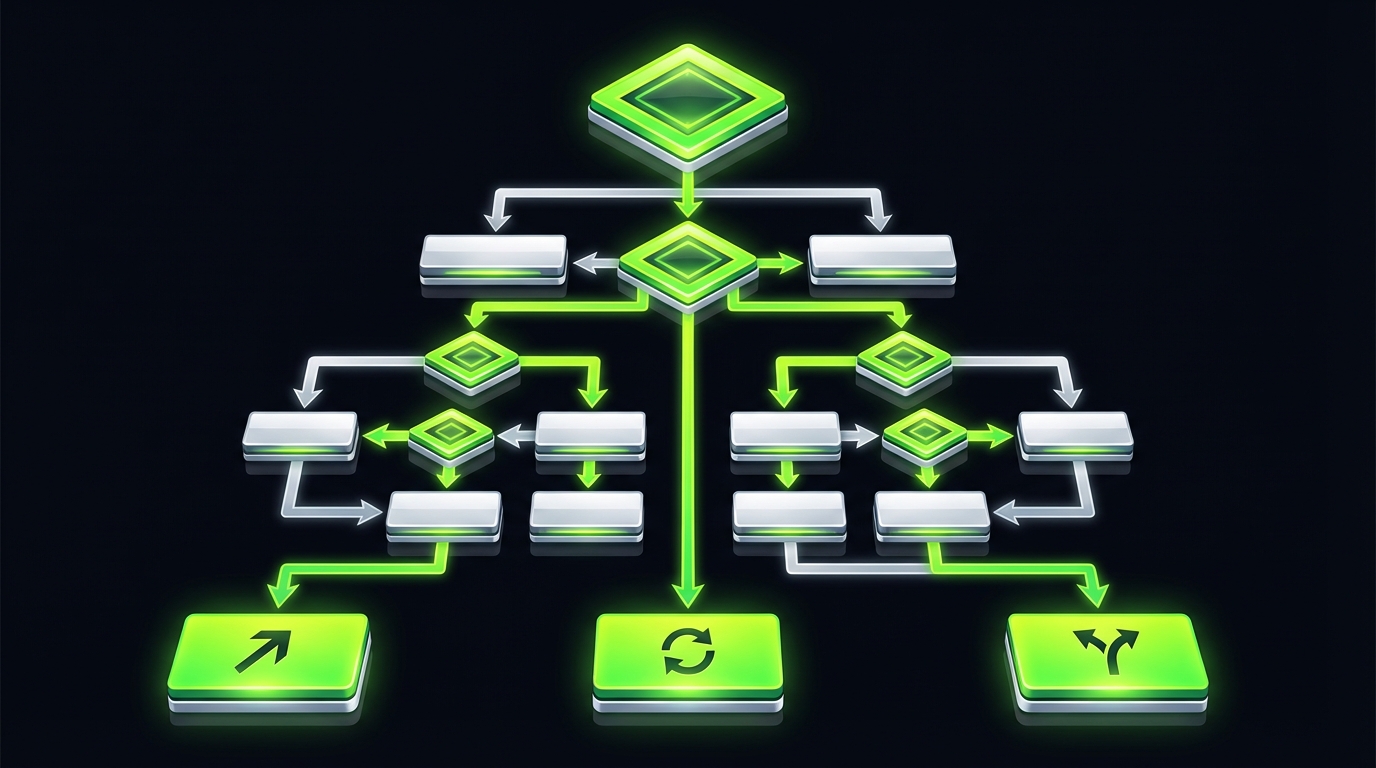
Decision tree: rewrite vs refactor
Use this in a 60 minute workshop. Do not overthink it. Answer with evidence.
- Are outages or compliance gaps existential?
- Yes: prioritize reliability controls first, then modernization.
- No: continue.
- Do you have automated tests around critical flows?
- No: refactor toward testability before large changes.
- Yes: continue.
- Can you create a seam (facade, gateway, module boundary)?
- No: favor refactor and modularization.
- Yes: continue.
- Is the domain stable for the next 12 months?
- No: incremental rewrite for the changing slice.
- Yes: refactor or modular monolith.
- Is the current platform a hard blocker (licensing, end of life, scaling ceiling)?
- Yes: incremental rewrite with strict cutover plan.
- No: refactor and extract only where needed.
If the team keeps answering “we do not know,” that is your first milestone: instrument, measure, and map dependencies.
A practical rule of thumb
Refactor when:
- You can improve safety with tests and boundaries
- The code still represents the business correctly
- Data is messy and you need time to understand it
Rewrite when:
- The current design makes correct changes too expensive
- You need a new runtime or deployment model
- You can isolate a slice and ship it behind a seam
Avoid big bang rewrites unless:
- The old system cannot legally or operationally run
- You have a proven migration path for every critical workflow
- You can afford a long period of dual run and heavy QA
Risk register template
Copy, paste, and use in sprint reviewUse this table as a living document. Update owners and status every sprint.
| Risk | Impact | Likelihood | Detection signal | Mitigation | Owner | Status |
|---|---|---|---|---|---|---|
| Data drift between old and new | Wrong reports, billing errors | Medium | Reconciliation mismatch rate | CDC or dual writes with idempotency, daily audits | Data lead | Open |
| Latency regression after extraction | Checkout drop, support tickets | Medium | p95 latency over threshold | Cache, query tuning, canary abort | Platform lead | Open |
| Hidden dependency in monolith | Cutover failure | High | Unexpected calls in tracing | Dependency mapping, strangler routing rules | Tech lead | Open |
| Rollback does not work | Extended outage | Low | Rollback drill fails | Regular rollback drills, blue green | SRE | Open |
| Compliance gap during migration | Audit failure | Low | Missing audit events | Compliance by design checks, log retention | Security | Open |
A safe cutover playbook
_> The sequence that keeps incidents contained
→ Scroll to see all steps
Data migration and cutover planning
Data is where modernization gets real.
Strangler Fig Playbook
Small slices, measured cutoversUse strangler fig when the system must keep running. It turns a risky cutover into a series of controlled routing changes. A practical sequence:
- Put a facade or gateway in front of the monolith (this is the seam).
- Choose one thin slice (one endpoint or workflow). Ship it end to end.
- Run shadow mode and compare outputs. Define what “match” means (tolerances, rounding, time windows).
- Do gradual routing (1% → 10% → 50% → 100%) with rollback triggers.
- Delete the legacy path. If you keep both forever, you are paying for permanent complexity.
Failure pattern to avoid: teams skip step 5 and call it “safety.” It is just two systems to maintain.
If you modernize code but keep the same broken data contracts, you will ship the same incidents faster.
A solid data migration strategy answers three questions:
- What is the source of truth today? Not what the docs say. What production says.
- How do we validate correctness? Row counts are not enough.
- How do we cut over and roll back? Without guessing.
Key Stat: The most expensive migration bugs are silent. They show up as wrong invoices, wrong permissions, or missing events days later.
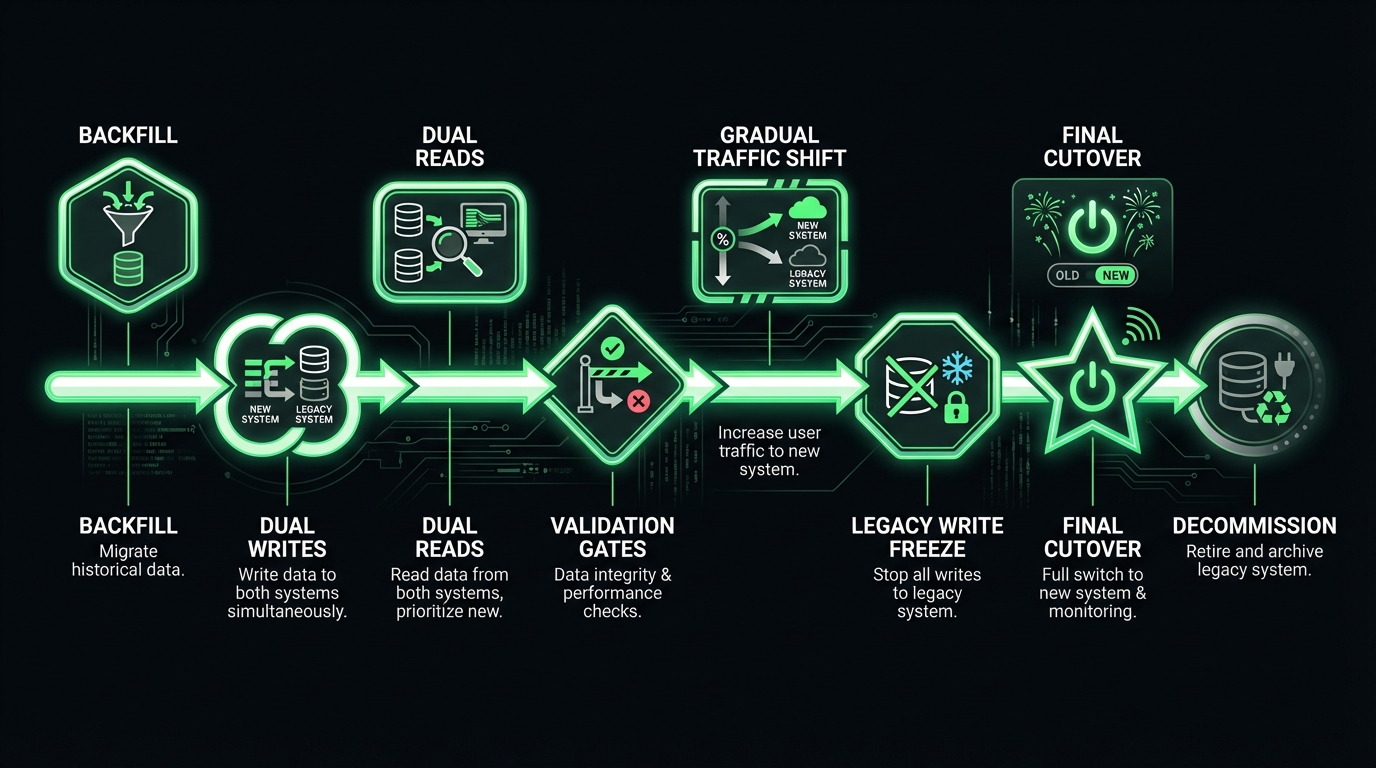
Data migration strategies that hold up
Pick a strategy per dataset. Do not force one approach everywhere.
Common strategies:
- Big bang backfill: migrate all data, then cut over
- Works for small datasets and low change rates
- Risky when writes happen constantly
- Dual writes: write to old and new stores
- Good for gradual cutover
- Hard to keep consistent without idempotency
- Change data capture: stream changes from old to new
- Strong for high volume systems
- Requires careful ordering and replay logic
- Event sourcing style rebuild: rebuild projections from events
- Great when you already have events
- Not a shortcut if you do not
Validation checks that catch real issues:
- Sample based field level comparisons on critical entities
- Reconciliation reports per business invariant (orders, payments, refunds)
- Permission and role audits for security sensitive tables
- Time window comparisons for analytics and reporting n If you are adding AI features during modernization, treat outputs as non deterministic. In our QA work on AI products, we test behavior with datasets and quality gates, not only single assertions. The same mindset applies to migrations: build a dataset of known tricky records and rerun it on every migration build.
Cutover planning, written down
A cutover plan should fit on one page and include:
- Cutover window and who is on call
- Feature flags and routing switches
- Data freeze rules, if any
- Validation gates and pass fail thresholds
- Rollback steps that work in 15 minutes
- Customer comms plan, even if you hope you will not use it
A simple cutover checklist:
- Confirm backups and restore drills are current
- Confirm dashboards for latency, error rate, queue lag
- Run a dry run in staging with production like data volume
- Execute cutover with a single incident commander
- Validate with pre agreed scripts
- Keep enhanced monitoring for 48 to 72 hours
What good looks like
_> Outcomes you can measure quarter over quarter
Faster change cycles
More frequent deploys with fewer rollbacks because seams and tests reduce fear.
Lower incident load
Smaller blast radius from canaries, feature flags, and clear rollback paths.
More trustworthy data
Reconciliation reports and validation datasets catch silent corruption early.
Cost clarity
You can attribute infra and operational cost per domain, then decide what to optimize.
Zero downtime patterns and reliability controls
Zero downtime is rarely one trick. It is a set of small controls that reduce blast radius.
Plan for Failure Modes
Protect the transition periodModernization usually fails because the business cannot tolerate the in between state, not because the new code is bad. Plan for these predictable costs and risks:
- Dual run cost (two systems, two bug queues). Put a weekly cap on how long a feature can require changes in both places.
- Data drift (Finance stops trusting reports). Define one source of truth per domain and measure mismatch rates, not just row counts.
- Shipping slowdown (everyone blocked on migration). Track lead time and deployment frequency during the migration, not after.
Use the article’s planning assumption: migration work is often underestimated by 2x to 5x until your own metrics prove otherwise.
Patterns that work in production:
- Blue green deployments with fast rollback
- Canary releases with automated abort
- Feature flags tied to business workflows, not only UI
- Backward compatible schemas during transitions
- Idempotent handlers for retries and duplicate messages
- Rate limiting and circuit breakers at service boundaries
Insight: If your rollout cannot abort automatically, it is not a canary. It is a slow motion outage.
Reliability controls to add early:
- SLOs for critical journeys
- Centralized logging with correlation ids
- Tracing across boundaries before you add more boundaries
- Runbooks for top 10 incident types
When we built large scale experiences like the ExpoDubai 2020 virtual platform that served 2 million global visitors, reliability work was not a phase at the end. It was a weekly habit: load testing, observability, and clear rollback paths. That is the mindset you want during modernization too.
KPI targets you can actually use
Set targets per journey, not only system wide averages.
Suggested starting targets (adjust to your domain):
- Latency (p95): 300 to 800 ms for core API calls
- Error rate: under 0.1% for customer critical endpoints
- Availability: 99.9% for revenue flows
- Cost per transaction: baseline first, then target 10% to 30% reduction over 2 to 3 quarters
Track these weekly:
- Deploy frequency
- Mean time to recovery
- Rollback rate
- Incidents per release
If you cannot hit targets yet, that is fine. The goal is trend lines, not perfection on day one.
Minimal reliability gate in CI
A lightweight gate that catches obvious regressions:
# Example: minimal SLO gate in CI (conceptual)
checks:
- name: smoke_tests
- name: migration_validation_dataset
- name: performance_budget
thresholds:
p95_latency_ms: 800
error_rate_percent: 0.1
- name: canary_plan_present
This is not about bureaucracy. It is about making unsafe changes harder to ship by accident.
Conclusion
Modernizing legacy systems without breaking the business is mostly about sequencing.
- Use the strangler fig approach to ship value early and reduce risk.
- Decide refactor vs rewrite with evidence, not preference.
- Treat data migration and cutover planning as first class engineering work.
- Bake in zero downtime patterns and reliability controls before you split the monolith.
Next steps you can take this week:
- Pick one critical journey and baseline latency, error rate, and cost.
- Draw the first seam for an incremental rewrite.
- Write a one page cutover plan, even if cutover is months away.
- Create a risk register and review it every sprint.
Final takeaway: A good legacy modernization strategy is boring on purpose. Small steps. Clear metrics. Fast rollback. Repeat.


