Introduction
You need capacity fast. A roadmap is slipping, a big customer is waiting, or a platform migration just became non optional.
Team augmentation can work. It can also create a second system: two backlogs, two definitions of done, and twice the coordination cost.
This guide is for engineering leaders who want speed without delivery chaos. It focuses on four failure points that show up in almost every staff augmentation onboarding:
- Onboarding that is “read the docs and ask questions”
- Ownership boundaries that stay implicit
- Quality standards that differ by team
- Communication cadence that explodes meeting time
Insight: If you can’t explain who owns what, how work gets accepted, and how incidents get handled, you don’t have a delivery model. You have hope.
We’ll use examples from projects where external teams had to integrate quickly and still ship production ready systems, including a luxury Shopify build delivered in 4 weeks (Miraflora Wagyu) and a large scale virtual event platform built under hard deadlines (ExpoDubai 2020).
What “rapid” should mean
Rapid is not “more people in Jira.” Rapid means:
- Time to first merged PR is measured in days, not weeks
- Time to first production release is planned and de risked
- Internal team throughput does not drop for two sprints
If you don’t track those, you’ll feel busy and still miss dates.
Key Stat: In Apptension delivery, we’ve shipped 360+ projects across industries. The pattern is consistent: the teams that measure onboarding and integration keep velocity. The teams that don’t, lose 1 to 2 sprints to coordination.
_> Proof points from delivery work
Useful numbers when you’re designing for speed and predictability
Where delivery chaos starts
Most chaos is not technical. It’s systems design, but for teams.
Common failure modes when you try to integrate contractors into agile teams:
- External engineers get a ticket, but not the context behind it
- Internal engineers become “API wrappers” for decisions and reviews
- QA becomes a negotiation instead of a gate
- Incidents expose missing ownership and missing runbooks
Insight: The fastest way to slow down is to add people without changing the operating model.
A quick diagnostic
If you answer “it depends” to more than two of these, expect friction:
- Who approves architecture changes?
- Who can merge to main?
- Who is on call for code written by externals?
- What is the definition of done for backend, frontend, and infra?
- What is the expected response time in Slack and PR reviews?
Budget and ROI reality check
Augmentation is often justified as “cheaper than hiring.” Sometimes it is. Often the real ROI is speed and risk reduction.
Track ROI with metrics that don’t lie:
- Cycle time (ticket start to production)
- Review latency (time waiting for review)
- Defect escape rate (bugs found after release)
- Incident ownership time (time until a named owner is engaged)
If you can’t improve at least two of these, you’re paying for motion.
Security and compliance pressure points
External contributors amplify two risks:
- Secrets and access sprawl
- Inconsistent controls across repos and environments
Treat augmentation as a security event, not an HR event:
- Least privilege access from day one
- Short lived credentials where possible
- Mandatory code owners and protected branches
- Audit trail for deployments and approvals
Insight: Compliance by design is cheaper than retrofitting controls after your first incident review.
Senior only staffing model
Why it reduces integration dragAdding capacity fast usually fails at the interfaces: unclear decisions, slow reviews, and inconsistent quality. A senior only model helps because seniors:
- Ask for constraints early (security, performance, compliance)
- Ship smaller slices and de risk integration sooner
- Need less “translation” from internal leads
Tradeoffs to plan for:
- Higher hourly cost
- Less tolerance for vague tickets
If the backlog is messy, fix ticket quality first. Otherwise you’ll burn senior time on clarification.
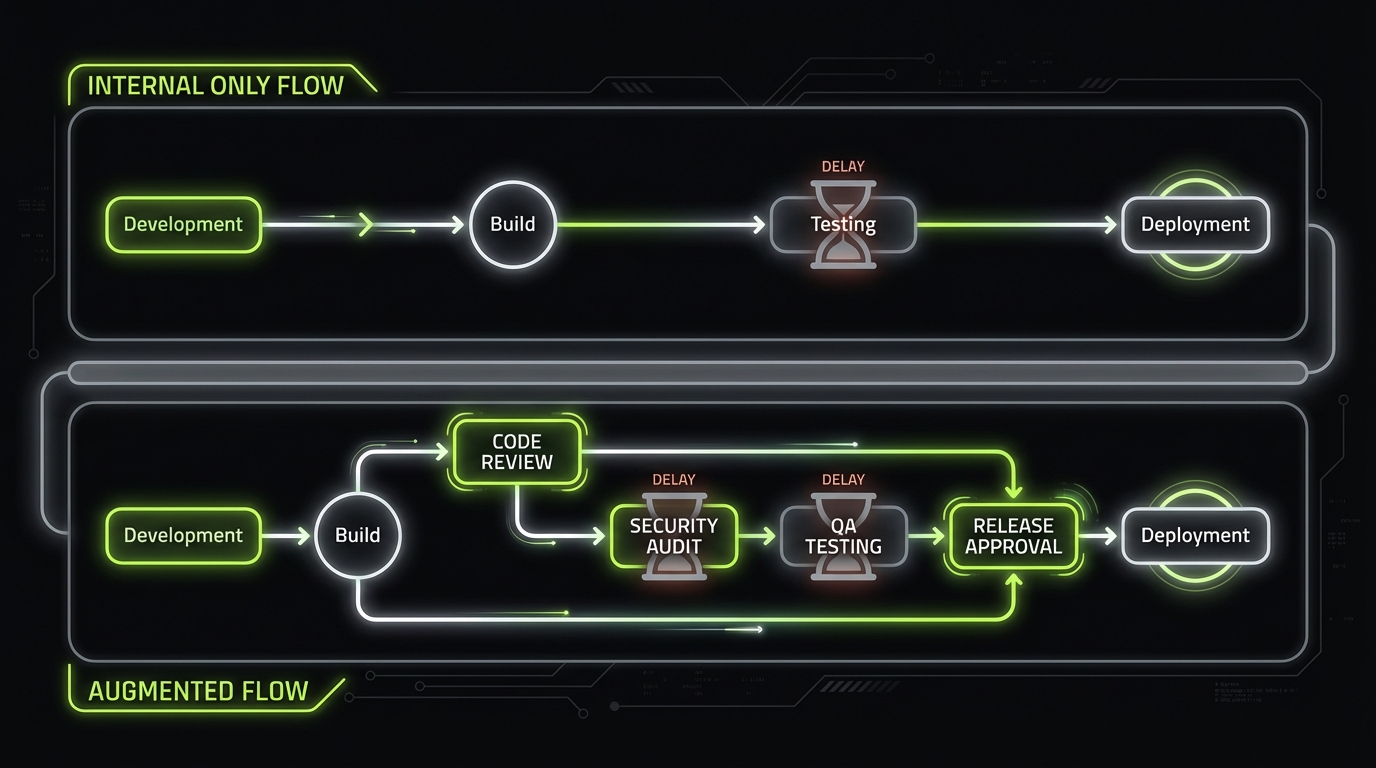
Rapid augmentation setup in 10 steps
_> A pragmatic sequence that avoids rework
→ Scroll to see all steps
Staff augmentation onboarding that works
Most onboarding fails because it is documentation heavy and decision light. External engineers need three things fast: context, constraints, and a safe first slice.
This is the onboarding playbook we’ve seen work best when speed matters.
Onboarding playbook for external engineers
Use a 5 day plan. Keep it boring. Boring ships.
- Day 1: Access and environment
- Repo access, CI visibility, staging access
- Local setup scripted (one command if possible)
- Secrets handled via vault or environment injection
- Day 2: Architecture and constraints
- System diagram and data flows
- Non negotiables: security, compliance, performance budgets
- Day 3: First PR
- A small, production relevant change
- Pair review with an internal owner
- Day 4: First end to end slice
- Feature flag on
- Observability included (logs, metrics, traces)
- Day 5: Ownership handshake
- Confirm code ownership boundaries
- Confirm on call and incident expectations
Example: On a fast Shopify delivery for Miraflora Wagyu, the team was spread across time zones. Asynchronous onboarding only worked once we made the first slice explicit: a single checkout and content path that could be reviewed and accepted quickly.

The “first PR” checklist
Your goal is not to test skill. Your goal is to test integration.
- PR touches a real production path
- PR includes tests or a clear test plan
- PR includes logging for key events
- PR follows repo conventions (lint, commit style, folder structure)
- PR is reviewed within 24 hours
If review takes 3 days, you don’t have an onboarding problem. You have a throughput problem.
What to document, what to demo
Documentation is necessary but not sufficient. Demo the stuff that is hard to infer:
- How releases happen
- How incidents are handled
- What “good” looks like in code reviews
- What gets rejected in security review
A 30 minute recorded walkthrough beats a 20 page wiki that nobody reads.
Augmentation readiness checklist
Use this before you add external engineers:
- One backlog and one definition of ready
- Protected branches and code owners configured
- CI gates run in under 15 minutes
- Environments documented (dev, staging, prod)
- Incident process documented (who pages who)
- Security access model defined (least privilege)
If you can’t check at least four, slow down and prepare. You’ll get the time back in sprint 2.
Ownership boundaries and collaboration contracts
If you want to integrate contractors into agile teams, you need explicit boundaries. Not because people are untrustworthy. Because ambiguity is expensive.
Make Ownership Explicit
RACI + collaboration contractImplicit ownership is expensive. "We all own it" often means orphaned services when production breaks. Write three contracts:
- Ownership: who owns code and decisions.
- Collaboration: response times, decision rules, escalation path.
- Support: who responds during incidents.
Use RACI for boring but risky areas: architecture changes, security sign off, release approvals, incident response. Keep it in one table and review it in kickoff. Hypothesis to validate: teams with a written collaboration contract cut waiting time by 20 to 40%. Measure PR review latency and blocked time in Jira before and after.
Think in contracts:
- Ownership contract: who owns what code and decisions
- Collaboration contract: how teams work together day to day
- Support contract: who responds when production breaks
Insight: “We all own it” is how you get orphaned services.
RACI patterns for shared ownership
RACI is boring. That’s why it works. Use it for:
- Architecture changes
- Security and compliance sign off
- Release approvals
- Incident response
Here’s a practical RACI you can steal.
| Activity | Internal Tech Lead | External Lead | Product Manager | QA Lead | Security | DevOps / Platform |
|---|---|---|---|---|---|---|
| Backlog refinement | A | R | R | C | C | C |
| Architecture decision record | A | R | C | C | C | C |
| Code review and merge | A | R | C | C | C | C |
| Release to production | A | R | C | C | C | R |
| Incident triage | A | R | C | C | C | R |
| Post incident review | A | R | C | C | C | C |
Legend: R Responsible, A Accountable, C Consulted
Collaboration contract template
Put this in a shared doc and review it in the kickoff:
- Response times: Slack within 4 business hours, PR reviews within 24 hours
- Decision making: ADR required for changes that affect data model, auth, or infra cost
- Escalation path: external lead -> internal tech lead -> head of engineering
- Definition of ready: ticket has acceptance criteria, test notes, and dependencies
Observation (hypothesis): Teams that write a collaboration contract cut “waiting time” by 20 to 40 percent. Validate by measuring PR review latency and blocked time in Jira.
Avoid the “shadow backlog”
A shadow backlog forms when externals track work in a separate tool or separate board.
Rules that prevent it:
- One backlog. One source of truth.
- External work is visible at the same granularity.
- Internal tech lead owns prioritization. Not the vendor.
If you need a separate board for billing, mirror it. Don’t split it.
Ownership boundaries that scale
Boundaries can be by:
- Service: external team owns a service end to end
- Layer: external team owns frontend or backend
- Capability: external team owns a feature area across services
Service ownership is usually the least chaotic. Layer ownership often creates review bottlenecks and unclear incident ownership.
Team augmentation best practices that hold up
_> Small rules that prevent big coordination costs
One backlog, one board
No shadow planning. All work is visible, prioritized, and estimated in one place.
Explicit PR review SLAs
Reduce idle time by setting review expectations and enforcing them.
Operational definition of done
Logs, metrics, and rollout plans are part of “done,” not a post sprint task.
RACI for decisions and incidents
Make accountability explicit before the first production issue hits.
Async first cadence
Written updates and decision docs reduce meetings and time zone friction.
Small slices, fast merges
Optimize for integration speed. Big PRs increase review latency and risk.
Quality standards and definition of done
Speed without quality gates is debt. Debt is fine if it’s intentional and priced in. Most teams don’t price it in.
5 Day Onboarding Plan
Context, constraints, first sliceDocumentation heavy onboarding fails because it delays decisions. A fast onboarding is decision light and output heavy. Use a 5 day plan with concrete outputs:
- Day 1: access + scripted local setup + CI and staging visibility.
- Day 2: system diagram + data flows + non negotiables (security, compliance, performance budgets).
- Day 3: first small PR, pair reviewed with an internal owner.
- Day 4: first end to end slice behind a feature flag, with logs, metrics, traces.
- Day 5: ownership handshake: code boundaries, on call, incident expectations.
Example: In our Shopify delivery for Miraflora Wagyu (4 weeks, time zones), async onboarding only worked once the first slice was explicit: one checkout and content path that could be reviewed and accepted quickly.
Definition of done that prevents rework
A usable definition of done has three parts:
- Functional: acceptance criteria met, edge cases handled
- Operational: logs, metrics, alerting, runbook notes
- Governance: security checks, privacy rules, audit trail
Here are definition of done examples you can adapt.
Definition of done example: API endpoint
- Endpoint meets acceptance criteria
- Contract documented (OpenAPI or equivalent)
- Unit tests added for core logic
- Integration test covers auth and error cases
- P95 latency budget defined and measured in staging
- Logs include request id and principal id
- Feature flag or safe rollout plan exists
Definition of done example: UI feature
- Works on target browsers and devices
- Accessibility checks completed for key flows
- Analytics event names agreed and implemented
- Error states and empty states included
- Visual regression risk assessed
Insight: If “observability” is not in your definition of done, incidents become archaeology.
Quality gates that don’t slow you down
Keep gates automated where possible:
- Lint, type checks, unit tests in CI
- SAST and dependency scanning
- Branch protection with required reviews
- Release checks tied to environments
If your gates are manual, they become politics.
# Example: minimal CI gate for augmented teams
# Goal: predictable merges, not perfect coverage
required_checks:
- lint
- typecheck
- unit_tests
- dependency_scan
required_reviews: 1
codeowners_required: true
protected_branches:
- main
AI features need different QA
If your product includes LLM or ML features, classic QA assumptions break. Outputs vary. Models drift. Vendor versions change.
In our QA work on AI heavy systems, we treat AI behavior as a product surface:
- Test datasets for “known tricky” prompts
- Automated judges for safety and correctness signals
- Drift monitoring in production
Example: When testing AI systems, the bug report often sounds like “it got worse,” not “step 3 throws a 500.” Your quality gates need to reflect that.
What fails in practice
Three common quality failures in augmentation:
- External engineers optimize for “merged” not “operated”
- Internal reviewers become the only quality gate
- QA becomes a separate phase at the end of the sprint
Mitigation:
- Put operational checks in the definition of done
- Make code owners explicit
- Review smaller PRs, more often
What you get when integration works
_> Outcomes to target and measure
Faster time to first release
External engineers ship production relevant slices within the first sprint, not the first month.
Stable internal throughput
Internal teams keep building instead of becoming full time reviewers and coordinators.
Lower incident ambiguity
Clear ownership and runbooks reduce time to engage the right people during outages.
Predictable quality
Definition of done and CI gates remove negotiation from acceptance and releases.
Communication cadence that keeps velocity
Meetings are not the enemy. Unbounded meetings are.
Chaos Starts in Ops
Add people, change the modelMost delivery chaos is not technical. It is missing operating rules. Common failure modes:
- Tickets arrive without context, so externals ship the wrong thing faster.
- Internals turn into "API wrappers" for decisions and reviews.
- QA becomes a debate, not a gate.
- Incidents surface the truth: no owner, no runbook.
Quick diagnostic: if you answer "it depends" to more than two, expect friction:
- who approves architecture changes 2) who can merge to main 3) who is on call for external code 4) definition of done by discipline 5) expected response times in Slack and PR reviews.
Mitigation: write the rules down before sprint 1. Then measure PR review latency and blocked time to see if the model is actually working.
The goal is a cadence that protects maker time and still keeps alignment.
Sprint rituals that work with external contributors
Keep the ritual set small and strict.
- Backlog refinement (60 minutes, weekly): internal tech lead + external lead + PM
- Sprint planning (60 minutes): commit to outcomes, not tasks
- Daily async standup: written update in a single thread
- Demo (30 minutes): show production like behavior, not slides
- Retro (45 minutes): one process change per sprint
Insight: If you add more rituals to “coordinate,” you often create the coordination problem you’re trying to solve.
Async standup template
Use three lines. Nothing else.
- What I shipped yesterday
- What I’ll ship today
- What’s blocked and who can unblock it
PR review service levels
If externals are waiting on internal reviews, you are paying for idle time.
Set explicit SLAs:
- Review requested before 12:00 gets first pass same day
- Otherwise within 24 hours
- If it’s blocked, reviewer writes the unblock steps, not “needs changes”
Time zones without pain
Time zones can work if you design for them.
- Two overlap windows per week for high bandwidth topics
- Everything else async with clear owners
- Recorded walkthroughs for complex changes
Example: In the Miraflora Wagyu build, the team spanned Hawaii to Germany. Early sync only meetings stalled decisions. Switching to async decision docs plus short overlap sessions kept progress moving.
When to add a checkpoint
Add a mid sprint checkpoint only if one of these is true:
- You have cross team dependencies that keep slipping
- You are changing architecture or data model
- You are onboarding multiple new engineers at once
Otherwise, it becomes another meeting with no decisions.
Conclusion
Rapid augmentation is an operating model. Not a staffing move.
If you want speed without chaos, make four things explicit:
- Onboarding playbooks that produce a first PR and a first slice fast
- Ownership boundaries backed by RACI and a collaboration contract
- Quality standards with a definition of done that includes operations
- Communication cadence designed to protect focus and reduce waiting
Next steps you can take this week:
- Write a one page collaboration contract and get sign off.
- Publish a definition of done for one critical work type (API, UI, infra).
- Measure PR review latency and blocked time for one sprint.
- Run a 5 day onboarding for the next external engineer and track time to first merged PR.
Final thought: If you can’t run the augmented team on a bad week, you don’t have a model yet. Build for the bad week. The good weeks will take care of themselves.