Introduction
Most regulated teams can build an AI prototype in a week. The hard part is shipping something that survives security review, audit, and day 30 of real users.
If you lead consulting delivery or platform engineering, you’ve seen the pattern:
- A demo looks great in a sandbox
- Legal asks where the data went
- Security asks what the model can be tricked into doing
- Risk asks how you will prove controls worked
- Support asks how to debug a bad answer at 2am
This guide is about getting from prototype to production ready AI in regulated industries. We’ll focus on AI compliance, an AI governance framework, and delivery practices that hold up in finance, healthcare, and defense.
Insight: In regulated environments, the model is rarely the risk. The system around it is.
You’ll also see a few concrete proof points from our delivery work. Across 360+ projects shipped since 2012, the consistent win is boring engineering: clear boundaries, measurable KPIs, and auditability from day one.

What “production ready” means here
For this article, production ready means:
- Repeatable deployments (infra as code, versioned configs)
- Traceable decisions (who approved what, which model, which prompt)
- Safe by default (least privilege, data minimization, guardrails)
- Measurable outcomes (quality, safety, cost, latency)
- Auditable behavior (logs that answer: what happened, why, and with which data)
If you can’t explain an output to a risk officer or an auditor, you’re not done.
_> Delivery proof points
Execution metrics we can stand behind
Why regulated AI fails
Teams don’t fail because they used an LLM. They fail because they ship an LLM like it’s a UI component.
Common failure modes we see in AI governance and delivery:
- Unbounded scope: “Chat with everything” becomes “exfiltrate anything”
- Data sprawl: prompts and logs quietly become a new sensitive datastore
- No evaluation plan: quality is judged by vibes, not by datasets and thresholds
- No traceability: you can’t reproduce an answer after a complaint
- Stakeholder mismatch: security wants controls, product wants speed, risk wants evidence
Key stat: If you only measure usage, you’ll miss the moment correctness drops and support load spikes. Track quality and safety alongside adoption.
Regulated context changes the rules
In LLM in finance compliance, you’re dealing with model risk management, record keeping, and sometimes suitability concerns. In LLM in healthcare compliance, you’re dealing with HIPAA, PHI boundaries, and clinical safety expectations.
A quick comparison helps align stakeholders early:
| Area | Finance focus | Healthcare focus | Defense focus |
|---|---|---|---|
| Primary risk | Misleading advice, fraud, audit findings | Patient harm, PHI exposure | Data classification, adversarial use |
| Key regs | GDPR, PCI DSS, internal MRM | HIPAA, GDPR, clinical policies | Export controls, internal security policies |
| Non negotiables | Traceability, approvals, retention | Data minimization, access control | Isolation, provenance, least privilege |
The “prototype trap”
A prototype often has:
- One prompt
- One happy path
- No red teaming
- No retention policy
- No rollback plan
That’s fine for discovery. It’s not fine for production.
What to align in week one
Before you write more prompts, align on:
- Intended use and forbidden use
- Data classes allowed in inputs and outputs
- Human in the loop points and escalation paths
- Evidence you must produce for audit
- KPIs and thresholds for rollout gates
If you can’t get agreement here, the fastest path is to shrink the scope until you can.
Production architecture patterns
_> Common building blocks that make audits easier
Policy and routing layer
Centralize rules for allowed tools, allowed data classes, and escalation paths. Keep policy versions and approvals traceable.
Retrieval with provenance
Index only approved corpora, store document IDs and hashes, and return citations. Treat retrieved text as untrusted input.
Tool broker service
Run tool calls behind an allowlist with scoped credentials. Log every tool input and output with a trace ID.
Strict output validation
Constrain outputs to schemas and validate before any downstream action. Fail closed for high risk workflows.
HITL queues
Route medium and high risk outputs to review queues with SLAs, reason codes, and two person approval where needed.
Observability and cost controls
Track token counts, latency, and cost per successful task. Add budgets, rate limits, and alerts per tenant.
Threat modeling for AI systems
Threat modeling is not optional in regulated AI. It’s how you turn “LLMs are risky” into a list of concrete controls.
Start with a simple rule: threat model the full system, not just the model.
A practical threat model (LLM app edition)
We usually map:
- Entry points: UI, API, batch jobs, internal tools
- Data flows: retrieval, tools, logging, analytics
- Trust boundaries: browser, app, VPC, third party model provider
- Assets: PII, PHI, payment data, credentials, proprietary docs
Then we test the obvious attacks:
- Prompt injection through user input and retrieved documents
- Data exfiltration through tool calls and verbose errors
- Indirect prompt injection from external content (emails, PDFs, web)
- Model output used as code or policy without validation
- Abuse: jailbreaks, toxic content, fraud scripts
Insight: Retrieval augmented generation can make prompt injection worse if you don’t treat retrieved text as untrusted input.
Controls that actually work
A short list of controls that tend to survive real usage:
- Allowlist tools. No dynamic tool discovery.
- Constrained outputs. JSON schemas, enums, strict validators.
- Content filtering at input and output, with reason codes.
- Policy prompts stored and versioned, not edited ad hoc.
- Least privilege for tool credentials and data access.
- Tenant isolation for embeddings and caches.
Here’s a minimal example of output validation that reduces “creative” failures:
from pydantic import BaseModel, Field
from typing import Literal
class Decision(BaseModel):
action: Literal["approve", "deny", "needs_review"]
rationale: str = Field(min_length=10, max_length=600)
citations: list[str] = Field(default_factory=list, max_length=5)
Red teaming that fits delivery timelines
You don’t need a six month program to start. You need a repeatable loop:
- Build an attack set (prompt injection, PHI bait, policy bypass)
- Run it on every release
- Track pass rate and top failure patterns
- Patch with controls, not longer prompts
Threat model outputs as audit artifacts
Save the outputs of your threat modeling as versioned artifacts:
- System diagram with trust boundaries
- Top threats with severity and mitigations
- Test cases you run in CI
- Residual risk and who signed off
That last line matters. In regulated environments, risk is often accepted, not eliminated.
What you get with governance first
Faster approvals
Security and compliance reviews go quicker when you can show artifacts: threat model, control mapping, and evaluation reports.
Lower incident load
Guardrails, validation, and HITL queues reduce escalations caused by incorrect or unsafe outputs.
Predictable costs
Token budgets, caching, and KPI based rollout gates prevent surprise spend as usage scales.
Easier vendor swaps
A gateway and versioned prompts make it practical to change models without rewriting product surfaces.
PII handling and data minimization
Most AI compliance issues show up as data issues. Not model issues.
Minimize data by default
Prompts are a datastoreMost compliance failures show up as data failures: prompts, logs, traces, and embeddings quietly become a new sensitive store. Practical rules:
- Do not send what you do not need. Strip identifiers before the model sees them.
- Separate identity from content. Use internal IDs, map back after the model step.
- Default to no retention. If retention is required, set explicit TTLs and access controls.
- Make logs safe. Treat traces like production data: classification, redaction, and audit access.
If you need a metric, start with: percent of requests containing PII or PHI (pre and post redaction), and retention coverage (what percent of stores have TTL enforced).
Data minimization rules that keep you out of trouble
These rules are boring. They also prevent most incidents:
- Don’t send what you don’t need. Strip identifiers before the model sees them.
- Separate identity from content. Use stable internal IDs, map back later.
- Default to no retention. If you must retain, set explicit TTLs.
- Make logs safe. Logs are data stores. Treat them that way.
Key stat: Treat prompts and traces as sensitive by default. Teams often discover they stored PII in logs only after a subject access request.
Patterns for PII and PHI
For LLM in healthcare compliance, assume every free text field can contain PHI.
Practical patterns:
- Client side redaction for obvious identifiers (email, phone, MRN)
- Server side classification for ambiguous text
- Tokenization for known identifiers (replace with placeholders)
- PHI safe retrieval: retrieve only the minimum necessary fields
A simple redaction pipeline can be staged:
- Regex and deterministic rules (fast, cheap)
- Named entity recognition (better coverage)
- Human review for high risk workflows
GDPR, HIPAA, PCI DSS touchpoints
You’ll likely need to document:
- GDPR lawful basis, purpose limitation, and DSAR process
- HIPAA BAAs where applicable, access controls, audit logs
- PCI DSS scoping if any payment data might enter prompts
If the answer is “we don’t process it”, prove it with controls and tests.
Vendor and deployment choices
You’ll face a decision: hosted model APIs vs private deployment.
| Option | Pros | Cons | When it fits |
|---|---|---|---|
| Hosted LLM API | Fast onboarding, strong base models | Data boundary concerns, vendor dependency | Low sensitivity, strong redaction, clear contracts |
| Private model in VPC | Control, isolation | Ops burden, model quality tradeoffs | Higher sensitivity, strict residency, defense contexts |
| Hybrid | Flexibility per workflow | Complexity | Mixed workloads, phased rollout |
In our experience, hybrid wins often start with hosted for pilot, then move sensitive workflows to private as evidence and budgets firm up.
Data contracts for AI features
Treat AI inputs and outputs as contracts:
- Allowed fields and data classes
- Max length and formats
- Retention rules per field
- Who can access traces
Write it down. Put it in code. Enforce it at boundaries.
Compliance by design checklist
Use this before your first pilotUse this as a working checklist during discovery and architecture.
AI compliance scope
- Identify applicable regs: GDPR, HIPAA, PCI DSS, internal policies
- Define intended use and prohibited use
- Define data classes allowed in input, retrieval, output, and logs
Security and threat model
- Document trust boundaries and entry points
- Add prompt injection tests (direct and indirect)
- Enforce tool allowlists and least privilege credentials
Privacy and data minimization
- Redact or tokenize identifiers before model calls
- Set retention rules for prompts, traces, and embeddings
- Confirm DSAR and deletion paths (where required)
Auditability
- Version prompts, policies, and retrieval indexes
- Capture trace IDs for every request
- Log human approvals and overrides with reason codes
Evaluation and MRM
- Define success metrics and thresholds
- Build a representative eval set with edge cases
- Add regression tests to CI for every prompt or model change
Operations
- Incident playbook and escalation routes
- Rollback plan for model and prompt versions
- Cost budgets and rate limits per tenant
Audit trails, traceability, and human controls
If you can’t answer “why did the system do that?”, you’ll struggle with AI governance and incident response.
Threat model the system
Controls that survive auditsIn regulated environments, the model is rarely the risk. The risk is the system around it: entry points, data flows, trust boundaries, and assets (PII, PHI, credentials). What to test every release:
- Prompt injection (user input + retrieved docs)
- Data exfiltration (tool calls, verbose errors)
- Indirect injection (emails, PDFs, web content)
Controls that tend to hold up in real usage:
- Allowlist tools (no dynamic tool discovery)
- Constrained outputs with schemas and validators (example: Pydantic model)
- Least privilege for tool credentials and data access
- Versioned policy prompts (no ad hoc edits)
Tradeoff: stricter constraints can reduce helpfulness. Track the delta: validator fail rate, manual review rate, and time to resolution for bad answers.
What to log (and what not to)
Log enough to reproduce behavior without creating a new privacy problem.
Log:
- Model name and version
- Prompt template version
- Retrieval sources and document IDs
- Tool calls with inputs and outputs
- Output validation results
- Policy decisions (blocked, allowed, escalated)
- Human actions (approve, edit, override)
Avoid:
- Raw PII in traces
- Full documents when IDs and hashes work
- Secrets and credentials
Insight: The fastest way to fail an audit is to have logs you can’t interpret, or logs you can’t legally keep.
Human in the loop done right
Human in the loop is not “someone can look at it”. It’s a designed control.
Common patterns:
- Review before action for high impact workflows (claims, payments, clinical notes)
- Two person approval for policy or prompt changes
- Escalation queues with SLAs and reason codes
- Editable drafts where humans remain the author of record
A simple decision policy helps:
- If confidence is high and risk is low, auto suggest
- If confidence is low or risk is medium, route to review
- If policy violation is detected, block and log
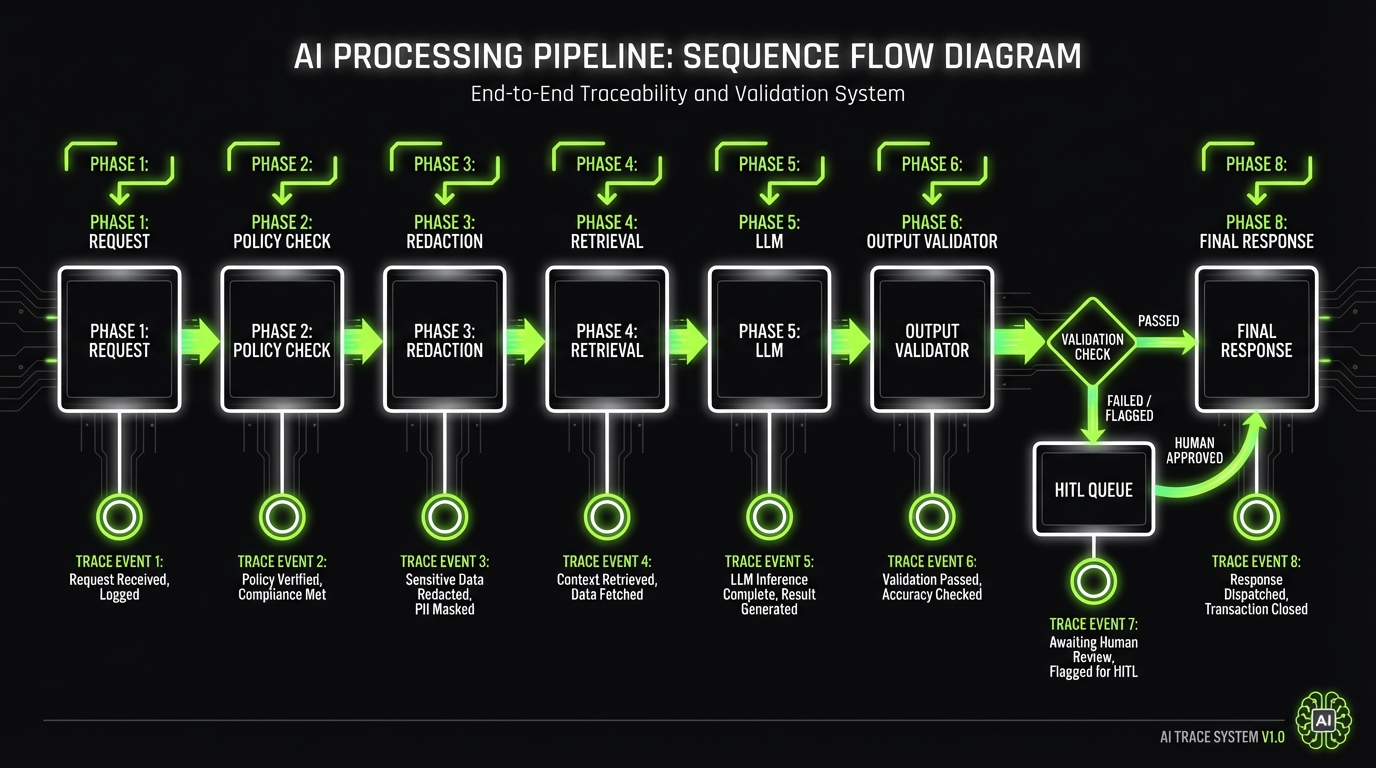
Traceability across the stack
Traceability is easier if you standardize an event schema.
Example event fields:
request_id,user_id,tenant_idmodel_id,prompt_version,policy_versionretrieval_set_id,doc_ids,doc_hasheslatency_ms,cost_estimate,token_countsdecision,decision_reason
This is also where tools like LangSmith style tracing help. The point is not the tool. The point is reproducibility.
Change management for prompts and policies
Treat prompts like code:
- Version control
- Code review
- Automated evaluation before merge
- Rollback plan
If a prompt change can alter behavior, it needs the same discipline as a business rule change.
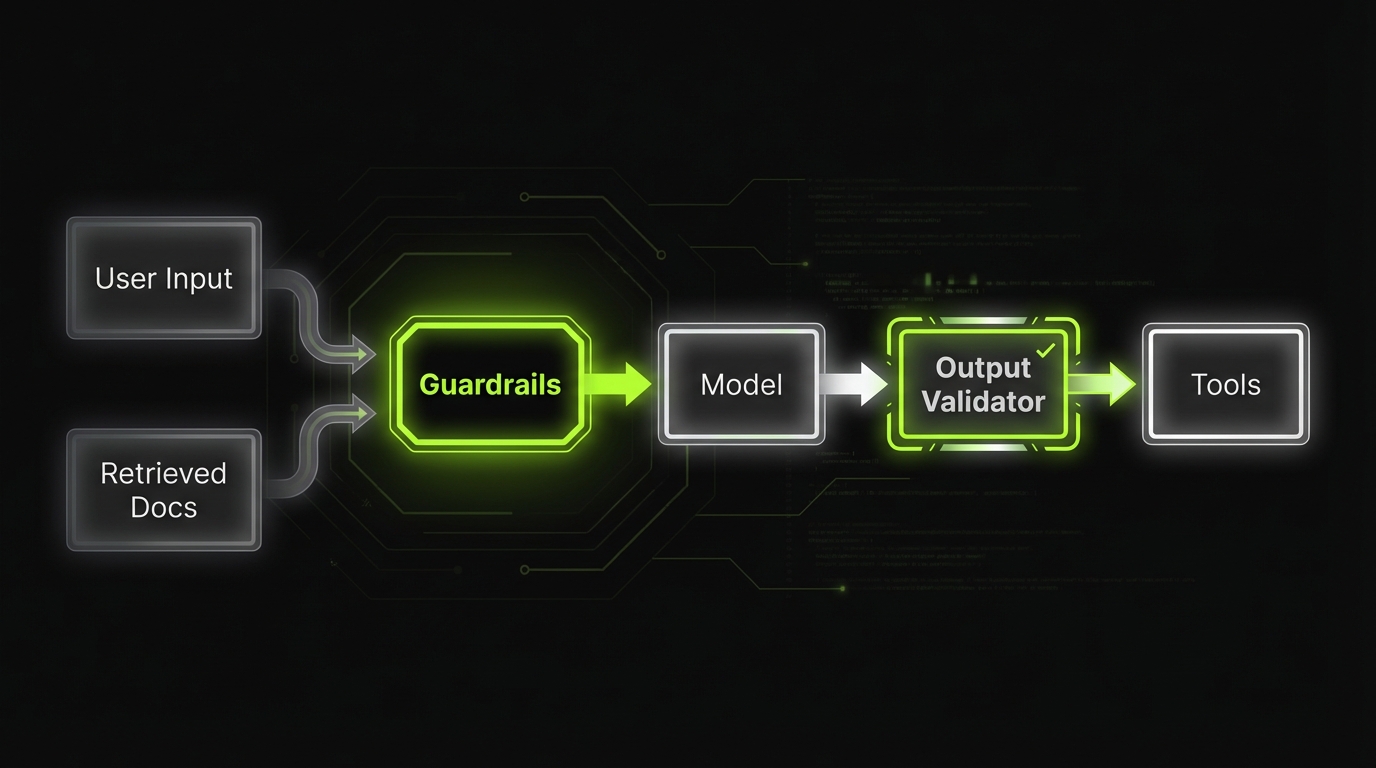
If you only take one pattern from this article, take this. A gateway service sits between product surfaces and any model provider. It typically owns:
- Authentication and tenant context
- Input validation and redaction
- Policy checks and routing rules
- Retrieval orchestration (or calls into retrieval service)
- Tool broker calls with allowlists
- Output validation and safety filters
- Structured logging and trace emission
Why it works in regulated environments:
- One place to enforce AI governance framework controls
- One place to add audit evidence
- One place to swap models without rewriting every client
Common pitfall:
- The gateway becomes a dumping ground. Keep it thin. Push domain logic to services with clear contracts.
Rollout stages
_> From pilot to scaled deployment without surprises
→ Scroll to see all steps
Evaluation frameworks and model risk management
Evaluation is where prototypes go to die. Or where production systems get boring and reliable.
Prototype trap checklist
What breaks after the demoA week one prototype usually has one prompt and one happy path. Production needs the boring parts:
- Scope bounds: define what the assistant will not do (tools, data sources, user roles).
- Evaluation plan: test sets, pass thresholds, and a release gate (not “seems good”).
- Traceability: store prompt versions, retrieval sources, tool calls, and outputs so you can reproduce a complaint.
- Ops basics: retention policy, rollback plan, and on call debugging path.
If you only track usage, you will miss the failure mode that matters: correctness drops, support load spikes. Measure quality and safety alongside adoption.
Build an evaluation stack, not a single score
We borrow the software testing analogy:
- Unit tests: validators, tool contracts, policy checks
- Integration tests: retrieval quality, tool execution
- End to end tests: realistic user journeys
- Adversarial tests: jailbreaks, injection, PHI bait
Example: On internal assistant style projects, we’ve seen teams get quick wins by adding tracing and a small curated evaluation set first, then expanding to automated regression suites as usage grows.
Model risk management (MRM) in practice
For LLM in finance compliance, expect MRM questions like:
- What is the model’s intended use and limitation?
- What datasets prove performance on your domain?
- How do you monitor drift and degradation?
- What is the fallback when the model fails?
A pragmatic MRM pack usually includes:
- Model card (intended use, limits, known failure modes)
- Evaluation report (datasets, metrics, thresholds)
- Control mapping (privacy, security, HITL)
- Monitoring plan (KPIs, alerts, incident playbook)
Monitoring KPIs: quality, safety, cost, latency
Track KPIs that map to business and risk. Here’s a starting table:
| KPI group | Metric | Why it matters | Typical owner |
|---|---|---|---|
| Quality | Task success rate, citation coverage, human edit rate | Shows usefulness and trust | Product, Ops |
| Safety | Policy violation rate, PHI leak rate, jailbreak pass rate | Shows risk exposure | Security, Compliance |
| Cost | Cost per request, tokens per success, tool call spend | Prevents surprise bills | Engineering, Finance |
| Latency | p50, p95, timeout rate | Protects UX and throughput | Engineering |
If you lack data, label it as a hypothesis and instrument it. For example:
- Hypothesis: “Citations reduce escalations.” Measure escalation rate with and without citations.
- Hypothesis: “Shorter context reduces cost without hurting quality.” Measure success rate vs token count.
Rollout stages: pilot to scaled deployment
Treat rollout as gated learning.
- Prototype: narrow workflow, synthetic data, no sensitive inputs
- Pilot: limited users, redaction on, tracing on, manual review
- Limited production: SLAs, incident playbook, automated eval gates
- Scaled deployment: multi tenant controls, cost controls, continuous red teaming
Each stage has exit criteria. Not dates.
Production architecture patterns for LLM apps
Most enterprise grade LLM apps converge on a few patterns:
- Gateway pattern: one service owns policy checks, redaction, routing, and logging
- RAG pattern: retrieval is isolated, versioned, and testable
- Tool broker pattern: tools run behind a broker with allowlists and scoped creds
- Async review pattern: high risk outputs go to a queue for human approval
The pattern choice depends on risk. Not preference.
Conclusion
Regulated AI delivery is not about finding the perfect model. It’s about building a system that can explain itself, restrict itself, and improve without surprises.
If you want a simple plan for the next 30 days, do this:
- Threat model the system and turn top risks into test cases
- Minimize data and treat prompts and traces as sensitive stores
- Add traceability so you can reproduce outputs and decisions
- Stand up evaluation with a small, high signal dataset and clear thresholds
- Roll out in stages with exit criteria tied to KPIs
Insight: The fastest teams ship sooner because they add controls early. They don’t bolt them on later.
In our delivery work, speed comes from self directed teams and clear gates. The same approach that let us ship a luxury Shopify build in 4 weeks and deliver a global virtual platform in 9 months also applies here: define the constraints, instrument everything, and keep scope tight until the evidence is strong.
If you’re aligning stakeholders right now, start with one question: what would you need to see in an audit to feel comfortable signing your name to this system?
That answer becomes your backlog.


