Introduction
Most teams don’t fail EU AI Act readiness because they ignore the law. They fail because they treat compliance as a document sprint at the end.
If your product has any AI in the loop, you need AI compliance by design. That means decisions you can explain, controls you can prove, and a delivery plan that matches the AI Act timeline.
This guide is written for product and engineering teams who need to ship.
You’ll get:
- A high risk vs limited risk classification workflow you can copy and run
- A product focused EU AI Act checklist for compliance by design
- Documentation and evidence pack templates for procurement and legal
- Architecture notes for logging, traceability, and controls
- A timeline driven roadmap that doesn’t stall delivery
Proof point: In Apptension delivery, we’ve shipped 360+ projects since 2012, including AI heavy products and enterprise platforms where auditability and operational controls mattered as much as features.
Who this is for
This is for teams who:
- Own an AI feature in production, not just a demo
- Need to answer procurement questions without scrambling
- Depend on vendors for models, hosting, data, or evaluation
- Want a plan that works even when the model changes
If you are still at PoC stage, you can still use this. You will just compress the timeline and focus on proving the riskiest assumptions first.
_> Delivery proof points
Numbers that matter when you plan an AI Act timeline
Classify risk fast
Risk classification is the first gate. Get it wrong and you either overbuild controls or underbuild evidence.
Here’s the practical approach: classify at the feature level, not at the company level. One product can have both limited risk and high risk components.
Insight: The fastest way to burn a quarter is debating definitions without mapping them to user journeys and decisions.

High risk vs limited risk workflow
Use this workflow as your default.
Inventory AI features
- List every place an AI output changes a user decision or system action.
- Include hidden flows: fraud flags, ranking, auto approvals, support macros.
Write the intended purpose
- One sentence.
- Example: “Suggest next best action for call center agents.”
Map the decision boundary
- What does the AI decide?
- What does a human decide?
- What happens if the AI is wrong?
Check for high risk triggers
- Does it touch regulated domains (employment, education, credit, insurance, critical infrastructure, essential services, law enforcement, migration, justice)?
- Does it materially affect rights, access, or safety?
Assign a preliminary class
- High risk: likely in scope for full high risk AI requirements.
- Limited risk: transparency duties still apply.
- Minimal risk: still do basic safety and QA, but don’t over engineer.
Validate with evidence
- Add concrete examples of decisions and harms.
- If you can’t describe harm, you can’t assess risk.
Copy, paste, run risk assessment worksheet:
Feature name: User group(s): Intended purpose (1 sentence): AI output type (score, label, text, ranking, action): Where it is used (screen/API/job): Decision boundary (AI vs human): Worst credible failure: Impact severity (low/medium/high): Likelihood (low/medium/high): High risk trigger domain (if any): Required transparency (what we tell the user): Required oversight (who can stop or override): Logging needed (inputs, outputs, model version): Vendors involved (model, hosting, data): Owner (PM/Eng/Legal): Status:Practical note: if you are unsure, treat it as high risk until you can prove otherwise. That keeps you honest about logging and oversight early.
Quick comparison table
Use this table to align product, legal, and engineering in one meeting.
| Topic | Limited risk | High risk |
|---|---|---|
| Typical obligation | Transparency and user information | Full control set plus documentation and governance |
| Product work | UI disclosures, user choice, basic logging | Risk management, human oversight, traceability, testing, monitoring |
| Evidence burden | Light to medium | Heavy, procurement ready |
| Common failure | Missing user disclosures | No audit trail, unclear responsibility, weak oversight |
| Best first step | Ship transparency copy and logging | Ship logging, override controls, and a risk register |
Key stat: If you can’t answer “which model version produced this output” in under 5 minutes, you are not audit ready. Measure it as an internal SLO.
Risk assessment workflow
Copy, paste, runUse this in a 60 minute working session.
- Pick one feature.
- Fill the worksheet fields.
- Decide preliminary risk class.
- List missing evidence.
- Create backlog tickets for controls and docs.
Tip: keep the output in a shared folder and link every ticket to it. That is how the evidence pack builds itself.
Timeline driven delivery roadmap
_> A practical AI Act timeline plan you can adapt
→ Scroll to see all steps
Build compliance by design
Compliance by design is not a separate track. It is product decisions expressed as:
Evidence pack from systems
Docs as engineering outputDocumentation drags when the system cannot produce evidence. Treat the evidence pack as a build artifact generated from logs, tests, and product decisions. Evidence sources to wire up:
- Logs that produce audit trails (who, what, when, which model version).
- Test pipelines that produce evaluation reports (repeatable runs, stored results).
- Product decisions that produce transparency copy (what the feature does, limits, user recourse).
Operational rule: assume the model can change underneath you. Measure (hypothesis): time to answer a procurement question with evidence should be hours, not weeks; track reproducibility pass rate on sampled outputs.
- Controls in the UI and API
- Logs and traceability in the platform
- Ownership in the org chart
When we build AI features, we treat them like products inside the product. They get their own acceptance criteria, QA datasets, and monitoring. This comes straight out of how we approach AI QA, where outputs are probabilistic and regressions can be silent.
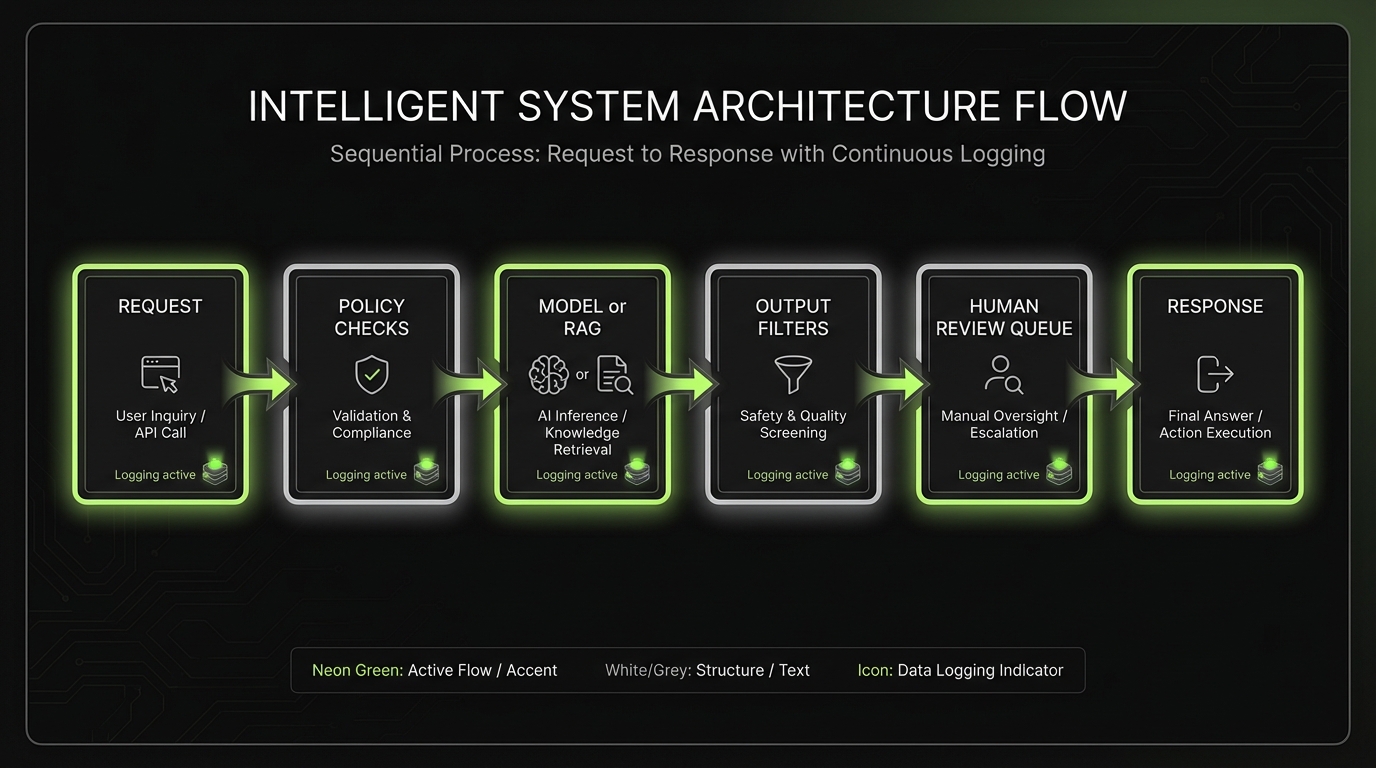
EU AI Act checklist for product teams
Use this as a working checklist. Add it to your backlog. Assign owners.
1) Product scope and user impact
- Each AI feature has an intended purpose statement
- Decision boundary is explicit (AI suggests, human decides)
- Known failure modes are listed (hallucination, bias, prompt injection, retrieval mismatch)
2) Transparency and user communication
- Users can tell when they are interacting with AI
- Disclosures match the channel (UI, email, voice)
- You document what the system can and cannot do
3) Human oversight
- There is an override and stop mechanism
- High impact actions require confirmation
- Escalation path exists for edge cases
4) Logging and traceability
- Inputs, outputs, and context are logged
- Model version, prompt version, and retrieval source hashes are logged
- Logs are access controlled and retention is defined
5) Quality and monitoring
- You have evaluation datasets for core tasks
- You measure drift and regressions after vendor updates
- You have incident runbooks for unsafe or wrong outputs
6) Supply chain
- Vendors are mapped to features
- DPAs and security terms cover AI usage
- You can switch vendors or degrade gracefully
Insight: The checklist is only useful if it changes sprint planning. If it lives in Confluence, it will not ship.
Human oversight patterns that work
Human oversight is not just “a human can review.” It is a design pattern.
Patterns we see work in production:
Human in the loop for high impact actions
- AI drafts.
- Human approves.
- System executes.
Two step confirmation
- AI suggests a decision.
- UI forces the human to confirm the reason.
- Good for approvals, denials, and eligibility.
Exception queue
- Most cases auto flow.
- Low confidence or policy flagged cases go to a review queue.
Stop the line button
- A visible control to disable AI output at feature level.
- Used during incidents and vendor regressions.
Counterfactual preview
- Show “what changed” and “why” before applying.
- Useful in ranking and recommendations.
Common failure modes and fixes:
Failure: reviewers rubber stamp because the queue is too big.
- Fix: tighten routing, sample review, and measure override rate.
Failure: no one owns the queue.
- Fix: assign an operational owner and set response time targets.
Failure: unclear accountability when AI is wrong.
- Fix: define RACI per feature and include vendor escalation.
Compliance by design building blocks
_> What to implement first for high risk AI requirements
Trace IDs everywhere
One identifier from UI to model call to storage. Makes audits and incident response possible.
Model and prompt registry
Versioned prompts, policies, and model configs. Lets you reproduce behavior and roll back safely.
Human review queue
A real workflow with SLAs, sampling, and ownership. Not a generic “someone can review.”
Kill switch per feature
Disable AI output without redeploying the whole system. Essential during vendor regressions.
Evaluation pipeline
Datasets, automated checks, and drift monitoring. Treat AI changes like releases.
Vendor change gates
Staging tests and signoff before accepting model version updates in production.
Documentation and evidence packs
Documentation is where most teams lose time. Not because writing is hard. Because the system was not built to produce evidence.
Controls you can prove
Compliance as product workTreat AI compliance as acceptance criteria, not a document sprint. In Apptension delivery, we’ve seen AI regress silently, so controls need to be testable and observable. Build into product and platform:
- UI and API controls: input constraints, user disclosures, safe defaults.
- Platform traceability: trace IDs, model and prompt version logging, policy checks before and after generation.
- Human oversight: a review queue for edge cases, shipped behind a feature flag.
What fails: “We will add oversight later.” Later becomes never. Mitigation: ship one oversight pattern early and measure override rate and escalation volume.
Treat documentation as output from your engineering system.
- Logs produce audit trails
- Test pipelines produce evaluation reports
- Product decisions produce transparency copy
Example: In AI QA work, we assume the model can change underneath us. That means evaluation and traceability need to be repeatable, not a one off PDF.
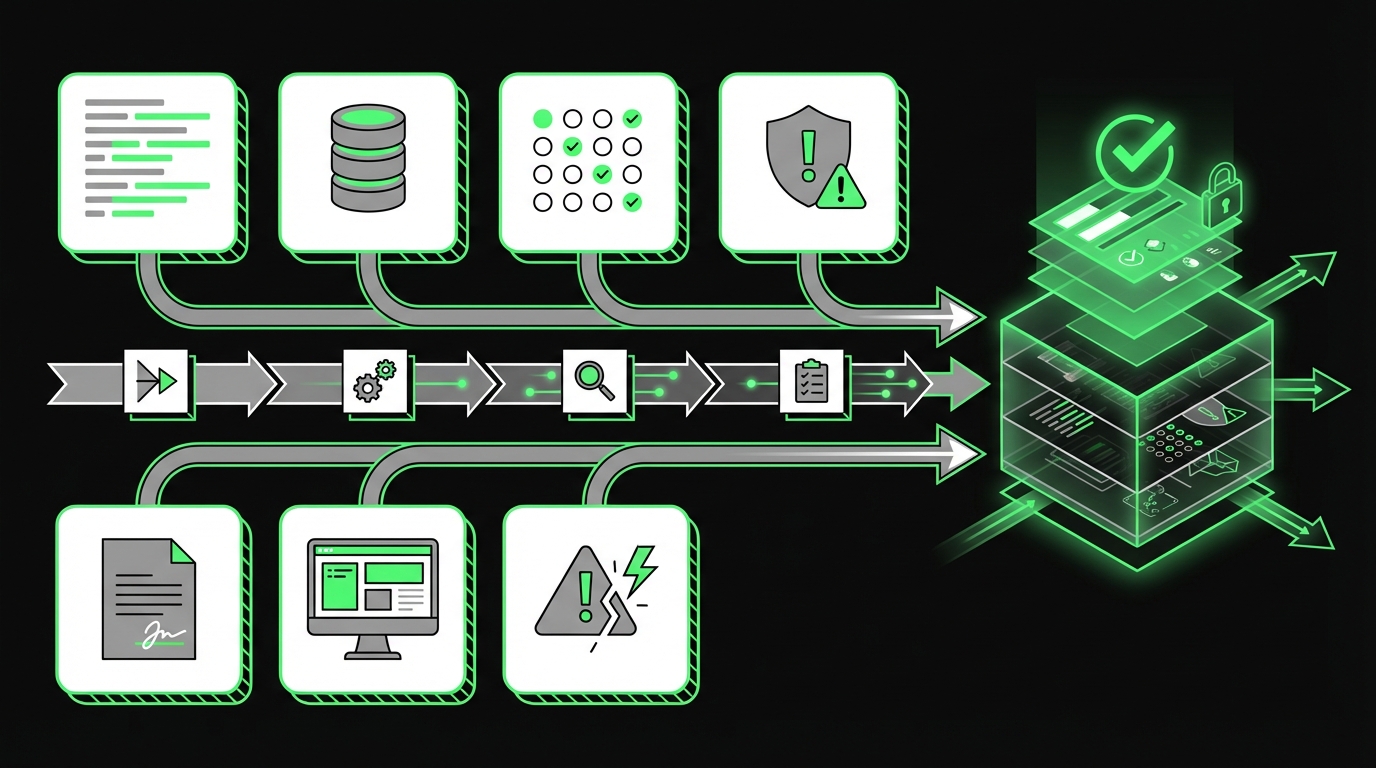
Documentation requirements: logs, transparency, oversight
Start with three buckets. They map cleanly to what procurement and legal ask for.
Logs and traceability
- Request and response payloads (with redaction rules)
- Model identifier and version
- Prompt and policy version
- Retrieval sources, document IDs, and chunk hashes for RAG
- Confidence scores and routing decisions
- Human actions: approve, edit, override, disable
Transparency
- User facing disclosures
- Limitations and intended use
- Data usage summary in plain language
- Contact path for complaints and corrections
Oversight
- Human review workflow
- Escalation and incident management
- Access control and role separation
- Monitoring metrics and alert thresholds
What fails in practice:
- Logging only outputs, not inputs and context
- No retention policy, so evidence disappears
- No mapping from a production event to a model version
Mitigation:
- Add a trace ID at the edge and propagate it through every hop
- Store model and prompt versions in a registry
- Define a minimum log schema and enforce it in code review
Evidence pack template for procurement and legal
Use this template as a folder structure. Keep it versioned.
01_Scope_and_intended_purpose/
feature_inventory.csv
intended_purpose_statements.md
02_Risk_management/
risk_register.xlsx
risk_assessments/
residual_risk_signoff.md
03_Data_and_training/
data_sources.md
data_quality_checks.md
labeling_process.md
04_Model_and_system/
model_cards/
prompt_registry_export.json
architecture_notes.md
05_Human_oversight/
oversight_workflows.md
reviewer_roles_and_training.md
override_and_stop_controls.md
06_Transparency/
user_disclosures.md
ui_screenshots/
support_playbooks.md
07_Testing_and_monitoring/
evaluation_datasets/
test_reports/
drift_dashboards_screenshots/
incident_runbooks.md
08_Vendors_and_supply_chain/
vendor_list.md
dpas_and_security_terms/
subprocessor_list.md
sla_and_uptime_terms.md
09_Operations/
access_control_matrix.xlsx
log_retention_policy.md
change_management.md
Keep it boring. Procurement likes boring.
Insight: If your evidence pack depends on one person who “knows where things are,” you have a single point of failure. Measure bus factor and fix it.
What usually fails
And how to avoid it- Teams log outputs but not versions, sources, or human actions.
- Oversight exists on paper but not in the UI.
- Vendor updates ship without staging evaluation.
- Documentation is written once and never updated.
Mitigation: treat AI features like dependency heavy systems. Version everything. Test on every change. Keep a kill switch.
Supply chain and architecture controls
Most AI products are supply chains.
Classify at feature level
Stop debating definitionsWhy this matters: Wrong classification wastes months. You either overbuild controls or ship without evidence. Run this workflow on each AI feature (not the whole product):
- Inventory the feature (where AI influences an output).
- Write the intended purpose in one sentence.
- List impacted users and who bears the downside if it fails.
- Identify the decision type (recommendation, ranking, eligibility, enforcement).
- Check high risk triggers against the user journey, not abstract labels.
Failure mode: Teams argue about “high risk vs limited risk” without mapping to decisions. Mitigation: Timebox classification to a workshop and produce a one page decision log per feature.
- Foundation model vendor
- Hosting and observability
- Data providers
- Labeling and evaluation tools
- Integrations that feed context into prompts
Your obligations do not stop at your code boundary.
In practice, the fastest way to de risk is to be explicit about responsibilities and to build technical controls that reduce vendor surprises.
Observation: Vendor model updates are a common source of silent regressions. Treat them like dependency upgrades with release notes, staging tests, and rollback paths.
Vendor and data responsibilities
Start with a simple RACI per feature.
- You own: intended purpose, user disclosures, oversight workflow, monitoring, incident response
- Vendor may own: model training process, base safety controls, infrastructure SLAs
- Shared: security, data protection, change notifications, evaluation during updates
Checklist for vendor and data governance:
- Subprocessors list is current and reviewed
- Data processing terms cover prompts, logs, and fine tuning
- You can export logs and evaluation artifacts
- You get change notifications for model version updates
- You have a fallback mode (disable AI, or use a smaller model)
- You have deletion and retention controls for user data
If you use retrieval augmented generation, add:
- Source documents have owners and update cadence
- You can trace an answer back to source IDs
- You can remove a document and confirm it stops appearing
Architecture notes: logging, traceability, controls
This is the minimum architecture set we recommend for auditability.
Logging schema (minimum viable)
trace_id timestamp user_id (or pseudonymous id) feature_id input_hash input_redaction_applied (true/false) model_provider model_name model_version prompt_version retrieval_index_version retrieval_source_ids policy_checks (list) output_hash output_classification (safe/needs_review/blocked) human_action (none/edited/approved/rejected) latency_msControls that pay off quickly
- Policy gate before model call (PII rules, disallowed intents)
- Output filters with explicit block reasons
- Review queue with sampling and SLA
- Feature flag kill switch
- Model registry and prompt registry
Table: traceability options and tradeoffs
| Option | What it gives you | What it costs | When to use |
|---|---|---|---|
| Simple request logs | Basic audit trail | Low | Limited risk features |
| Full trace with versions | Reproducibility | Medium | High risk AI requirements |
| Event sourcing for decisions | Strong accountability | High | Regulated workflows and approvals |
| External tracing tool | Debug speed | Medium | Multi service systems |
Key stat: Aim for a measurable internal target: “Reproduce any AI output within 24 hours using the same inputs, versions, and sources.” Track pass rate.
What good readiness buys you
Faster procurement cycles
You answer questionnaires with evidence, not opinions. Less back and forth with legal and security.
Fewer production incidents
Versioning, monitoring, and stop controls reduce blast radius when the model shifts or retrieval changes.
Clear accountability
Decision boundaries and oversight patterns make it obvious who can override, who reviews, and who owns outcomes.
More predictable delivery
Compliance work becomes backlog items with acceptance criteria, not a last minute scramble.
Conclusion
EU AI Act readiness is a delivery problem. You need classification, controls, and evidence that stay true after the first release.
If you do one thing this week, do this:
- Run the classification workflow on your top 3 AI features.
- Add trace IDs and version logging end to end.
- Pick one human oversight pattern and ship it behind a feature flag.
- Start an evidence pack folder and keep it versioned.
What to measure next:
- Time to answer a procurement question with evidence (hours, not weeks)
- Override rate and escalation volume
- Regression rate after model or prompt changes
- Reproducibility pass rate for sampled outputs
Final insight: Compliance by design is not slower. It is what keeps you shipping when the first incident hits.

Next steps checklist
- Assign an owner per AI feature
- Create a risk register and review it monthly
- Add a stop mechanism and document who can use it
- Build a repeatable evaluation pipeline, not a one time test
- Map vendors to features and document shared responsibilities


