Introduction
RAG systems fail in ways that look fine in a demo and painful in production.
The common pattern is predictable:
- Retrieval returns something plausible but wrong
- The model fills the gaps with confident text
- Users stop trusting the tool, even when it is right
This guide is about RAG evaluation that holds up after launch. Not a one off benchmark. A system that catches regressions, explains failures, and supports hallucination reduction over time.
Insight: If you cannot explain whether a bad answer came from retrieval or generation, you cannot fix it. You can only tweak prompts and hope.
In our delivery work, we have seen this most clearly on RAG heavy products like LEDA, an AI driven exploratory data analysis tool built in 10 weeks. The hard part was not wiring up an LLM. The hard part was shipping behavior that stays reliable when indexes change, prompts evolve, and models get upgraded.
You will leave with:
- A scorecard you can copy into your repo
- A benchmark design method that starts from support tickets
- A debug playbook to isolate retrieval vs generation failures
- Release gates and production monitoring patterns that do not depend on vibes
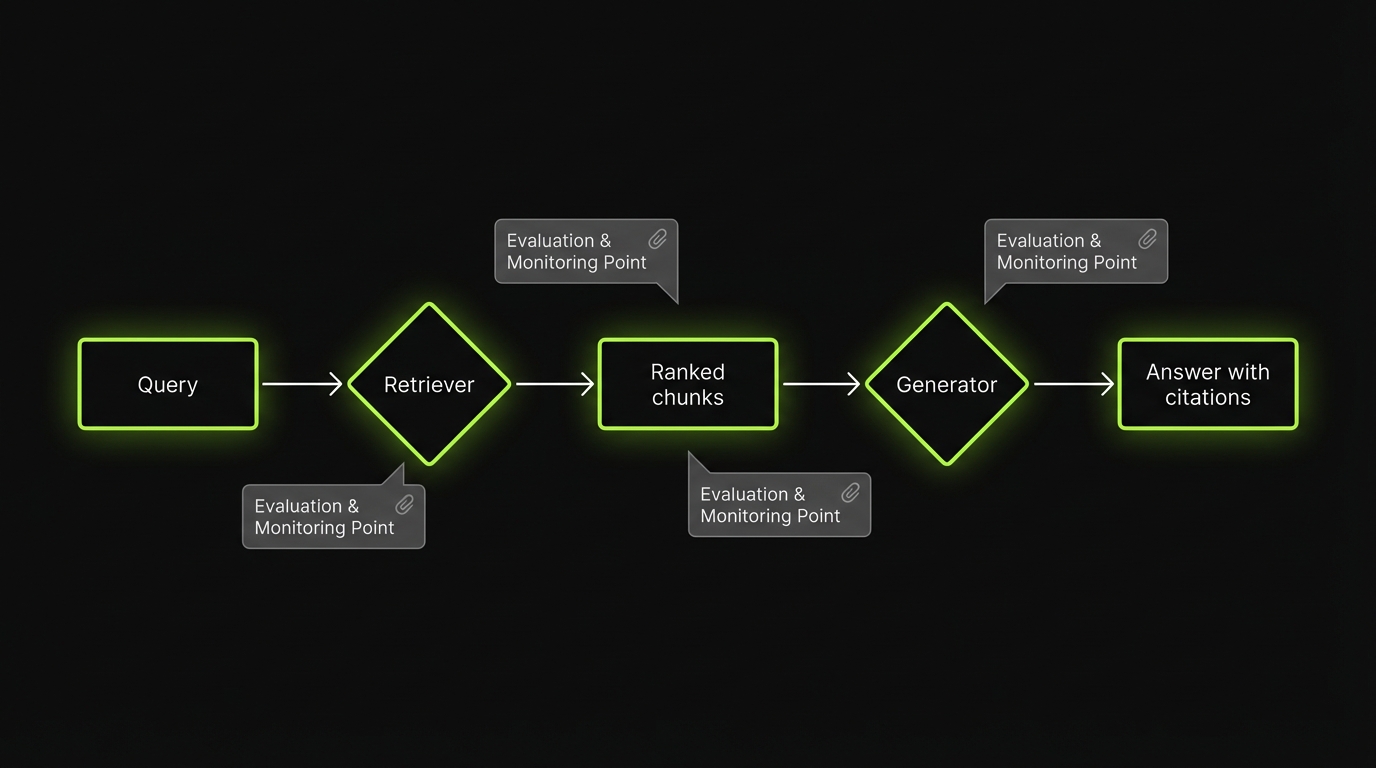
What quality means in RAG
For RAG, quality is not one number. It is a set of constraints:
- Find the right evidence (retrieval)
- Use the evidence correctly (generation)
- Stay stable across changes (regression testing)
- Detect drift fast (RAG monitoring)
If you only measure end to end “answer looks good,” you will miss the failure mode that matters most: the model sounding correct while being ungrounded.
_> Proof points we plan around
Delivery scale and quality targets we use in practice
Build offline eval sets
Offline eval sets are your source of truth. They are also where most teams cut corners.
A useful set is not “50 random questions.” It is a curated mix that forces the system to prove it can:
- retrieve the right context
- refuse when context is missing
- handle ambiguous and adversarial phrasing
Key stat: In QA work on AI products, the biggest time sink is not writing tests. It is arguing about what “correct” means after a regression.
Start small. Ship with 100 to 300 cases. Grow it every sprint.
Ground truth: what counts as correct
Define ground truth in a way that can be checked.
Good ground truth formats:
- Answer plus supporting span: expected answer and the exact source snippet that justifies it
- Allowed answer set: multiple acceptable phrasings, plus required facts
- Tool output contract: for agentic flows, expected tool calls and key fields
Avoid ground truth that is only “a good explanation.” That becomes subjective fast.
Checklist for each ground truth case:
- What is the user trying to do?
- What sources are allowed?
- What facts must appear?
- What facts must not appear?
- What citations are required?
Negative cases: teach refusal
Negative cases are where LLM groundedness becomes real.
Include cases where the correct behavior is:
- “I don’t know based on the provided sources”
- “I can’t answer that without data X”
- “This is out of scope for this knowledge base”
Common negative case types:
- Missing document
- Outdated policy
- Conflicting sources
- User asks for private data
A simple rule: at least 20 to 30% of your eval set should be negative or abstention cases. Treat that ratio as a hypothesis if your domain differs, then measure user satisfaction and escalation rates.
Edge cases: where RAG breaks
Edge cases are not rare. They are just underrepresented.
Add cases for:
- Short queries: “refund?”
- Long queries with multiple intents
- Entity ambiguity: same name, different product lines
- Numeric questions: thresholds, limits, dates
- Format constraints: “answer in a table,” “give me three bullets”
A practical source is your own backlog:
- Pull the last 50 support tickets or analyst questions
- Label which ones are RAG eligible
- Convert the top failure clusters into test cases
That is benchmark design that stays aligned with business value.
Offline RAG evaluation workflow
_> A repeatable loop that fits into sprints
→ Scroll to see all steps
Measure retrieval quality
If retrieval is weak, generation cannot save you. It can only guess.
Release gates and regressions
CI checks, not vibesRAG quality shifts without code changes: index rebuilds, model upgrades, prompt edits, new docs. Treat eval like CI. Test layers separately (prompts, retriever and ranking, chunking and embeddings, model version, post processing) so failures are diagnosable. A release gate that holds up:
- No drop in recall at 20 on the golden set beyond a set threshold
- No increase in unsupported claims on groundedness checks
- Citation precision above a minimum bar on high risk topics
- Negative case refusal rate stays stable
- Cost and latency stay within budget
If a gate fails, ship behind a feature flag. End to end tests alone will catch regressions late and still leave you guessing where they came from.
Retrieval metrics sound academic until you map them to user pain:
- Low recall means “it never finds the right doc”
- Low precision means “it finds too much noise”
- Low MRR means “the right chunk is buried”
- Low coverage means “whole topic areas are invisible”
Insight: Most hallucinations start as retrieval failures. Fixing retrieval often reduces hallucinations more than prompt tuning.
Use a table to keep the team aligned on definitions and thresholds.
| Metric | What it checks | How to compute | Typical failure signal |
|---|---|---|---|
| Recall at k | Did we retrieve any relevant chunk? | relevant in top k | Users say “it missed the doc” |
| Precision at k | How much of top k is relevant? | relevant divided by k | Answers cite irrelevant sources |
| MRR | How high was the first relevant chunk? | 1 divided by rank | Good evidence exists but is ranked low |
| Coverage | Are key topics represented? | topics with passing recall | Entire product areas underperform |
Implementation notes that matter:
- Define “relevant” at the chunk level, not the document level
- Track metrics by query cluster, not only global averages
- Version your index and embedding model so you can reproduce results
Recall, precision, MRR, coverage
A simple starting point:
- For each eval question, store a set of relevant chunk IDs
- Run retrieval with fixed k values, like k equals 5 and k equals 20
- Compute recall at k and precision at k
- Compute MRR to catch ranking regressions
- Compute coverage by tagging each question with a topic
If you lack chunk level labels, start with document level, but treat it as a temporary compromise. Document level labels can hide chunking problems.
Retrieval metric pitfalls
Watch for these traps:
- Chunk leakage: evaluation labels match the old chunking scheme, but you changed chunk size
- Query leakage: test questions are too close to document headings, so retrieval looks better than reality
- Over tuning to the set: you tune retriever parameters until the benchmark looks great, then production questions still fail
Mitigation:
- Keep a hidden holdout set
- Rotate in fresh cases from new tickets monthly
- Report confidence intervals when the set is small
Core metrics to implement
_> If you track nothing else, track these
Recall at k
Tells you if the system can find the right evidence at all. Start with k equals 20 for most corpora.
MRR
Catches ranking regressions where the right chunk exists but is buried.
Coverage by topic
Prevents silent failures where entire product areas underperform while averages look fine.
Unsupported claims rate
A groundedness proxy that correlates with hallucination reduction when tracked over time.
Citation precision
Measures whether citations actually support claims. Critical for user trust.
Negative case refusal accuracy
Ensures the assistant declines when evidence is missing or the request is unsafe.
Measure answer quality
Answer quality is where product teams usually argue. Make it measurable.
Retrieval metrics to track
Hallucinations often start hereIf retrieval is weak, generation can only guess. Track retrieval with metrics that map to user complaints:
- Recall at k: did we retrieve any relevant chunk? (Users: “it missed the doc”)
- Precision at k: how much of top k is relevant? (Users: “it cites noise”)
- MRR: how buried is the first relevant chunk? (Users: “the answer ignores the right source”)
- Coverage: which topic areas never pass recall? (Users: “this area always fails”)
Implementation details that prevent false confidence:
- Define relevance at the chunk level, not document level
- Report metrics by query cluster, not only global averages
- Version the index + embedding model so you can reproduce drops after rebuilds
Based on delivery experience on RAG heavy products like LEDA, fixing retrieval often reduces hallucinations more than prompt tweaks, because the model stops filling gaps with confident text.
For RAG, the core answer metrics are:
- Faithfulness: does the answer match the provided context?
- LLM groundedness: does every factual claim trace back to sources?
- Citation quality: are citations correct, specific, and actually supportive?
Example: On RAG based analytics tools like LEDA, we saw that users forgave slower answers. They did not forgive answers that cited the wrong chart or table.
A practical approach is to score answers with both automated checks and human review.
- Automated checks catch regressions fast
- Human review catches “technically grounded but unhelpful” responses
Use a rubric. Do not rely on a single LLM judge score.
# Pseudocode: evaluation record for one test case
case = {
"query": "What is our refund window for subscription plans?",
"retrieved_chunk_ids": ["doc12#c3", "doc12#c4"],
"expected": {
"must_include_facts": ["30 days"],
"must_not_include": ["lifetime"],
"required_citations": ["doc12#c4"]
},
"metrics": {
"recall_at_5": 1,
"mrr": 1.0,
"faithfulness": 0.9,
"citation_precision": 1.0,
"abstained": False
}
}
That record is what makes debugging and regression testing possible.
Faithfulness vs groundedness
Teams mix these up.
- Faithfulness asks: given the retrieved context, did the model stay consistent with it?
- Groundedness asks: are the claims supported by that context, with no extra facts?
A model can be faithful to irrelevant context. That still produces a wrong answer.
How to score quickly:
- Faithfulness: label each sentence as supported, contradicted, or not addressed by context
- Groundedness: count unsupported claims and weight by severity
Severity examples:
- Low: wrong adjective
- Medium: wrong threshold or date
- High: wrong compliance or policy statement
Citation quality checks
Citations are not decoration. They are part of the contract.
Check:
- Citation precision: cited chunks actually support the claim
- Citation recall: key claims have citations
- Citation specificity: chunk level, not “whole document”
Common failure patterns:
- Citation points to a nearby but irrelevant paragraph
- Model cites a source that contradicts the answer
- Citations exist, but the answer includes extra uncited facts
If your UI shows citations, add a UX test: can a user click and verify the claim in under 10 seconds?
Release gates, not hope
A simple policy for shipping RAG changesUse feature flags for anything that changes retrieval or generation. Minimum gate set:
- Retrieval recall at 20 does not regress on the golden set
- Unsupported claims do not increase on groundedness checks
- Citation precision stays above the bar on high risk topics
- Negative case refusal behavior stays stable
If a change fails a gate, you can still merge it. You just do not roll it out broadly.
Regression testing and release gates
RAG quality shifts without code changes. Index rebuilds. Model upgrades. Prompt edits. New documents.
Eval sets that matter
Start from real failuresOffline eval sets are your source of truth, but only if they are curated. Skip “50 random questions.” Build a mix that forces the system to (1) retrieve the right chunk, (2) refuse when context is missing, and (3) handle ambiguous or adversarial phrasing. Practical baseline:
- Ship with 100 to 300 cases, then add new cases every sprint
- Pull new items from support tickets and production transcripts (not brainstorms)
- Write down what “correct” means up front (otherwise regressions turn into debates)
What fails if you cut corners: the team can detect a regression, but cannot agree on what broke or why. Measure that time sink explicitly (hypothesis): time to triage a failed case should drop as the set matures.
So you need regression tests that run like any other CI check.
Test these layers separately:
- Prompts
- Retrievers and ranking
- Chunking and embeddings
- Model versions
- Post processing, like citation formatting
Insight: If you only run end to end tests, you will detect the regression late and still not know where it came from.
Here is a release gate that works for most teams shipping enterprise grade RAG.
Release gate checklist:
- No drop in retrieval recall at 20 on the golden set beyond an agreed threshold
- No increase in unsupported claims on groundedness checks
- Citation precision above a minimum bar on high risk topics
- Negative case refusal rate stays stable
- Cost and latency within budget
If you cannot meet a gate, ship behind a feature flag. Do not ship to everyone.
RAG evaluation scorecard template
Copy this into a doc and fill it in. Keep it short enough that people actually use it.
| Category | Metric | Target | Current | Notes |
|---|---|---|---|---|
| Retrieval | Recall at 20 | >= 0.90 | Golden set | |
| Retrieval | MRR | >= 0.70 | Ranking stability | |
| Retrieval | Coverage | >= 0.85 | By topic tags | |
| Answer | Groundedness unsupported claims per answer | <= 0.2 | Weighted by severity | |
| Answer | Faithfulness | >= 0.85 | Sentence level rubric | |
| Answer | Citation precision | >= 0.90 | Chunk level | |
| Safety | Refusal accuracy on negative set | >= 0.95 | No unsafe compliance advice | |
| Ops | P95 latency | <= budget | Track by tenant | |
| Ops | Cost per 1k queries | <= budget | Include reranks |
Two rules:
- Put owners next to each row in your internal version
- Track by segment. Global averages hide pain
Benchmark design: from tickets to test cases
Benchmarks rot when they are disconnected from real usage.
A simple pipeline:
- Export support tickets, analyst questions, and chat transcripts weekly
- Cluster by intent and topic
- Pick the top 5 clusters by volume and by business risk
- Write 5 to 10 test cases per cluster
- Add at least one negative case per cluster
What to store per case:
- query
- expected must include facts
- allowed sources
- relevant chunk IDs
- risk tag, like billing, compliance, security
This is also how you explain prioritization to stakeholders. You are not “improving the model.” You are reducing failures in the top complaint clusters.
Debug playbook: retrieval vs generation isolation
When an answer is wrong, isolate the failure before you change anything.
Debug steps:
- Check retrieval first
- Did top k contain any relevant chunk?
- If yes, was it ranked low? Look at MRR.
- Check chunk quality
- Is the relevant fact split across chunks?
- Is the chunk too large, too small, or missing tables?
- Check generation
- Does the model ignore the chunk?
- Is the system prompt conflicting with the instruction?
- Check citations
- Are citations attached to the right sentences?
- Is post processing reordering or truncating text?
A quick triage table helps:
| Symptom | Likely root cause | First fix to try |
|---|---|---|
| No relevant chunk in top 20 | embeddings, filters, query rewrite | adjust filters, improve query normalization |
| Relevant chunk exists but ranked low | ranking, hybrid search weights | add reranker, tune lexical vs vector balance |
| Good chunks retrieved, answer still wrong | prompt, model, context window | tighten instructions, reduce distractors |
| Correct answer, wrong citations | citation mapping bug | sentence to chunk alignment tests |
Do not start with prompt tweaks. They often hide retrieval problems and make future regressions harder to diagnose.
What to log per request
So you can debug in minutes, not daysLog these fields for every RAG response:
- Query, normalized query, and detected intent
- Retriever config version, index version, embedding model version
- Top k chunk IDs with scores and ranks
- Prompt version and model version
- Output text, citations, and abstention flag
- Latency and cost estimates
This is the minimum for credible RAG monitoring and regression analysis.
What improves when evaluation is solid
_> Outcomes you can measure, not just feel
Faster debugging
You can attribute failures to retrieval, chunking, ranking, prompt, or model changes with logs and layer specific tests.
Safer releases
Regression gates stop quality drops from reaching users, especially on high risk topics like billing and compliance.
Better user trust
Citation quality and groundedness reduce the “sounds right but wrong” problem that kills adoption.
Lower long term cost
You spend less time in prompt whack a mole and more time improving the highest volume failure clusters.
Conclusion
RAG quality is not a single pass. It is a loop: offline eval, regression gates, and RAG monitoring in production.
If you want evaluation that holds up, focus on what you can control:
- Build an offline set with ground truth, negative cases, and edge cases
- Track retrieval metrics that explain failures: recall, precision, MRR, coverage
- Track answer metrics that drive trust: faithfulness, LLM groundedness, citation quality
- Run regression testing on prompts, retrievers, and models
- Monitor drift, run feedback loops, and alert on changes that matter
Next steps you can do this week:
- Create a 100 case golden set from your last 50 to 100 tickets
- Add 25 negative cases that force refusal
- Implement recall at 20 and citation precision in CI
- Add a release gate that blocks shipping when those regress
- Set up production dashboards for topic coverage and unsupported claim rate
The goal is simple: fewer wrong answers, faster debugging, and a system your users keep trusting after the first week.
Production monitoring that matters
Monitoring is where most RAG systems either mature or quietly die.
Track:
- Drift: changes in query mix, topic distribution, and retrieval scores
- Feedback loops: thumbs down, rewrites, escalations, and “show me sources” clicks
- Alerting: spikes in abstentions, unsupported claims, or missing citations
A practical alert list:
- Recall at 20 drops more than X on a key cluster after an index rebuild
- Citation precision drops on high risk topics
- P95 latency increases after enabling reranking
- Feedback negative rate exceeds baseline for a tenant
Treat thresholds as hypotheses. Start conservative. Tighten after you have two to four weeks of baseline data.


