Introduction
ISO 42001 is showing up in procurement calls for the same reason SOC 2 did. Buyers want proof that your AI is controlled, not just impressive.
The problem is predictable. Teams hear “AI governance” and picture committees, paperwork, and a release train that never leaves the station. Meanwhile product still needs to ship. Security still needs answers. Legal still needs a record.
This guide is about ISO 42001 in practice. Delivery terms. Concrete artifacts. Workflows your engineers will actually follow.
Insight: If governance does not produce a decision in under a week, teams route around it. That is how you end up with governance theater.
What we’ve seen across 360+ projects delivered is that the fastest teams don’t skip controls. They make controls part of the delivery system.
In this article you’ll get:
- An AI management system described like a delivery operating model
- A risk workflow you can run every sprint: intake, assessment, mitigation, review
- An ISO 42001 checklist of minimum artifacts that speed procurement
- Practical controls for data, models, vendors, and changes
- A mapping approach from governance controls to product requirements

What this is and is not
This is not a clause by clause interpretation of the standard. It’s a delivery guide that helps you:
- Answer procurement questionnaires faster
- Keep an auditable trail without slowing releases
- Reduce avoidable incidents: unsafe outputs, data leaks, vendor surprises
If you want one mental model: treat ISO 42001 like compliance by design for AI features, not a separate program that runs after engineering.
_> Delivery proof points
What we track when governance must keep up with shipping
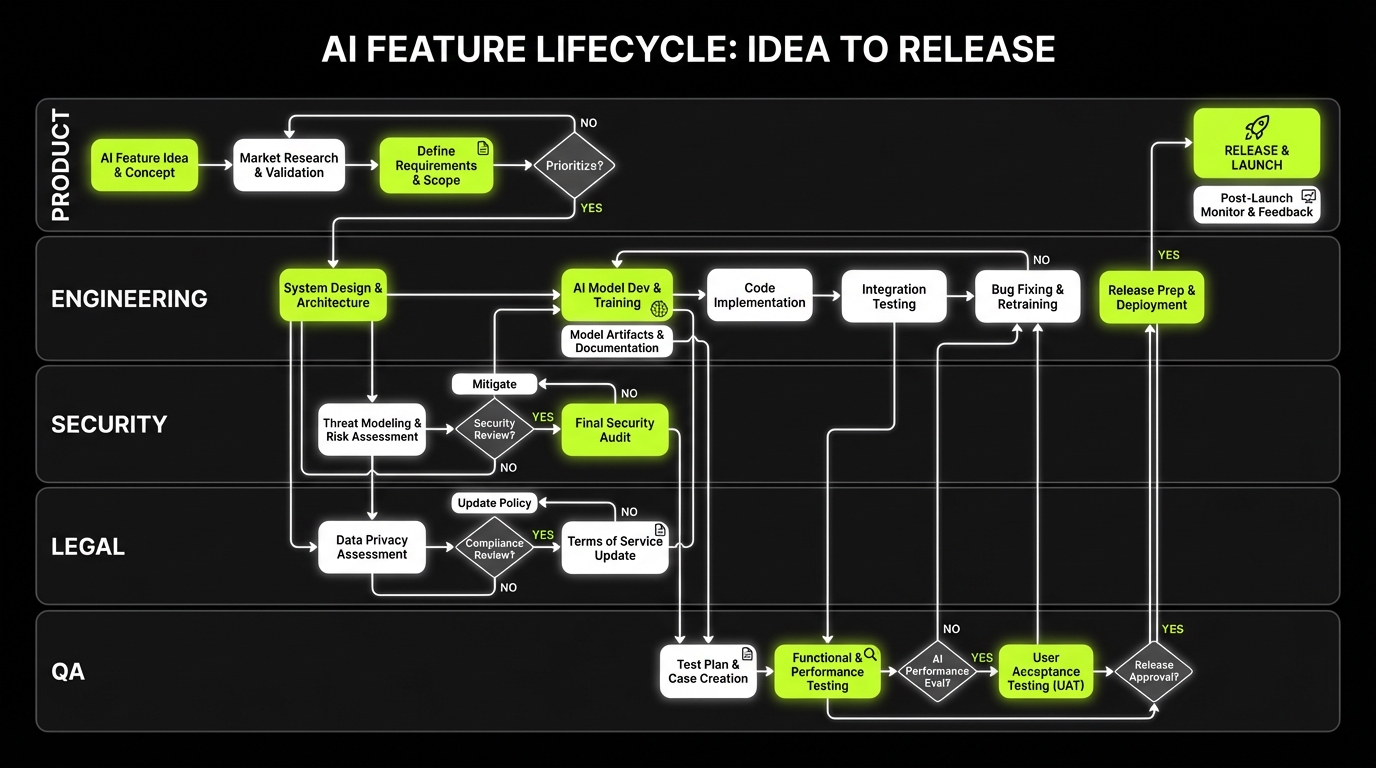
An AI management system that ships
An AI management system is not a wiki page called “AI policy.” It’s the set of routines that decide:
- What you will build
- What risks you accept
- What evidence you keep
- Who can approve what
If it’s working, you can point to a product release and show how governance influenced it.
Delivery view, not org chart
A practical AI management system has four layers:
- Intent: why the AI exists, who it serves, what “good” means
- Controls: guardrails for data, models, vendors, and changes
- Execution: how teams build, test, release, and monitor
- Evidence: what you can show an auditor or a buyer without scrambling
Here’s what that looks like in a product repo and delivery cadence:
- A single AI feature spec template used by PMs and engineers
- A risk intake form that opens a ticket and assigns an owner
- A lightweight approval gate for high risk changes only
- Automated checks in CI for prompt, model, and retrieval changes
- A monitoring dashboard tied to user impact and cost
Example: In our AI delivery work (for example, building an AI driven exploratory data analysis tool in 10 weeks using RAG), the fastest progress came after we made “evidence” a first class output. Each iteration produced a test set update, a decision record, and a release note tied to model and data versions.
The minimum system boundary
ISO 42001 gets easier when you draw a boundary. Define what is in scope:
- AI assisted features inside your product (chat, summarization, recommendations)
- Data pipelines that feed those features (training, fine tuning, retrieval)
- Third party services (LLM APIs, vector DB, annotation vendors)
Then define what is out of scope for now. Be explicit. Auditors and buyers prefer a clear boundary over a vague promise.
What to measure to prove it works
If you can’t measure governance outcomes, you’ll measure activity instead. That is where theater starts.
Track a small set of metrics:
- Risk cycle time: days from intake to decision
- Change failure rate: percent of AI releases rolled back due to behavior regressions
- Incident rate: user reported safety or correctness incidents per 1,000 sessions
- Procurement turnaround: days to answer AI security and compliance questions
If you don’t have baseline data, call it a hypothesis and start collecting it next sprint.
Use this operating model as a starting point. Adjust names, keep the mechanics. Roles
- AI Product Owner: owns intended use, user impact, and acceptance criteria
- AI Tech Lead: owns architecture, model choices, and change controls
- AI Risk Owner: owns the risk record and mitigation tracking (often Security or GRC)
- QA Lead: owns evaluation plan, test sets, and regression thresholds
- Legal and Privacy: consulted for data sources, retention, and vendor terms
Cadence
- Weekly risk triage (30 minutes): new intakes, re ratings, mitigation status
- Per release evaluation run: required for medium and high risk changes
- Monthly review (45 minutes): incidents, drift, vendor changes, backlog pruning
Escalation rules
- If a feature can cause financial harm, safety harm, or regulated impact, escalate to an explicit sign off.
- If monitoring shows threshold breach for two days, freeze changes and run a review.
- If a vendor changes model behavior without notice, trigger vendor reassessment and consider fallback.
What makes this work is one constraint: every escalation must end in a written decision record.
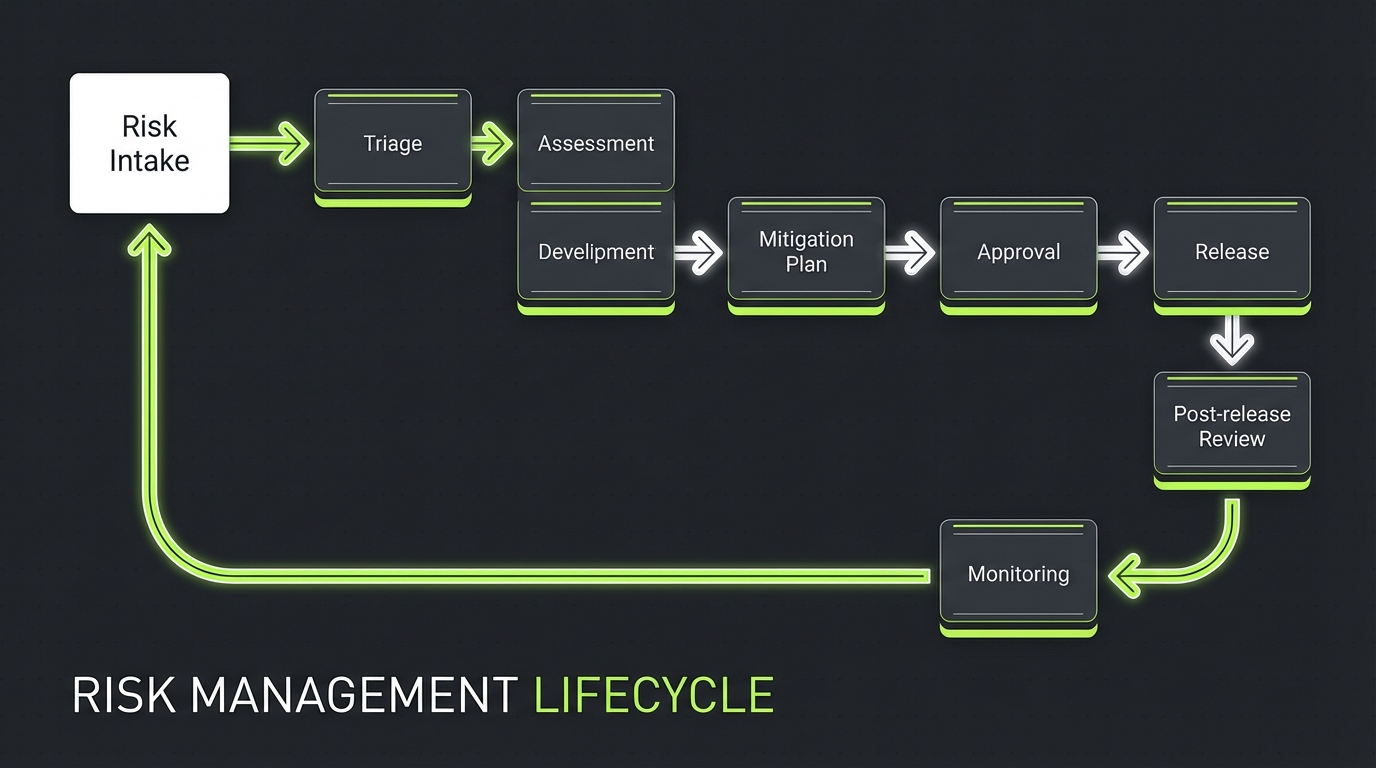
Risk management workflow
_> Intake, assessment, mitigation, review in a single loop
→ Scroll to see all steps
Risk workflows you can run weekly
Most teams overthink risk management. You don’t need a 40 page model. You need a workflow that runs every week.
Procurement artifact pack
Answer buyer questions fastBuyers do not want opinions. They want reusable evidence. A tight artifact pack cuts repeat security questions because you answer consistently: data used, model used, change control, evaluation, and incident handling. Minimum ISO 42001 artifacts teams actually maintain:
- AI policy and scope (one page)
- AI system inventory
- Risk register (with review dates)
- Data register (lawful basis, retention, access)
- Model and prompt register (versions, eval results)
- Change log (what changed, why, approvals)
- Evaluation plan + test sets
- Monitoring + incident process (SLAs, postmortems)
- Vendor assessments
- Training and role guidance
Example (delivery context): In a 4 week luxury Shopify store build, decisions had to be written down to move across time zones. Same rule applies here: document once, reuse everywhere. Failure mode: Artifacts live in a compliance tool engineers never open. They rot. Keep them close to the repo and release process.
A good AI governance framework makes risk handling boring:
- It starts at intake
- It produces a decision
- It creates a mitigation plan
- It gets reviewed after release
Insight: Risk work fails when it’s detached from product work. Put it in the same ticketing system, with the same SLAs.
1) Intake
Intake is where you prevent surprise AI from shipping.
Minimum intake fields:
- Feature name and user journey
- Model type (rules, ML, LLM, RAG)
- Data sources (first party, third party, user provided)
- User impact if wrong (annoying, harmful, financial, legal)
- Deployment context (internal tool, customer facing, regulated workflow)
Implementation detail that matters: intake should create a ticket with an owner and due date. No forms that die in inboxes.
2) Assessment
Assessment is a structured conversation. Keep it consistent.
Use a simple scoring model with clear thresholds. Example dimensions:
- Safety: potential for harmful guidance or unsafe actions
- Privacy: exposure of personal or confidential data
- Security: prompt injection and tool misuse risk
- Fairness: disparate impact on user groups
- Reliability: hallucination, inconsistency, drift
- Compliance: sector rules, contractual requirements
A practical output is a one page risk record:
- Risk statement
- Score and rationale
- Decision: accept, mitigate, avoid
- Owner and review date
Callout: In QA for AI products, “it got worse” is a real bug report. Your assessment should define what “worse” means using measurable checks like task success, groundedness, and refusal accuracy.
3) Mitigation
Mitigation should be a backlog, not a paragraph.
Typical mitigations that work in production:
- Add retrieval citations and enforce “answer from sources only” for knowledge tasks
- Add input and output filters for unsafe content
- Add rate limits and anomaly detection for tool calls
- Add human in the loop for high impact decisions
- Add canary releases for model and prompt changes
When mitigations are expensive, make the tradeoff explicit:
- What risk remains?
- Who signs off?
- What monitoring will catch regressions?
4) Review
Review is where you close the loop.
Run a short post release review on a fixed cadence:
- Weekly for high risk features
- Monthly for medium risk
- Quarterly for low risk
Review inputs:
- Incident log
- Monitoring metrics
- Drift signals (model change, data distribution shift)
- Customer complaints and support tickets
Review outputs:
- Updated risk record
- Updated test set
- Decision to continue, adjust, or roll back
Artifacts that speed procurement
Procurement does not want your opinions. They want evidence.
Weekly risk workflow
Same tickets, same SLAsRun risk like sprint work. Keep it in the same system as product tickets, with owners and deadlines. Workflow (minimum): Intake → Triage → Assessment → Mitigation plan → Approval (only if high risk) → Release → Post release review. What to measure (hypothesis):
- Time from intake to decision (target: under 7 days).
- Percent of high risk changes that shipped with an approved mitigation plan.
- Post release incidents per release and time to close.
Common failure mode: Risk reviews happen in a separate tool or meeting series. Evidence gets stale. Engineers stop updating it.
A tight artifact pack can cut days off security reviews because you can answer the same questions consistently:
- What data do you use?
- What model do you use?
- How do you control changes?
- How do you test for bad outputs?
- What happens when something goes wrong?
Example: In fast turnaround builds like a luxury Shopify store delivered in 4 weeks, the only way to move that quickly across time zones is to write decisions down. The same habit applies to AI governance. Document once, reuse everywhere.
ISO 42001 artifact pack: minimum set
This is the ISO 42001 checklist we see teams actually maintain without resentment.
- AI policy and scope (one page)
- AI system inventory (systems, owners, model types, vendors)
- Risk register (with review dates)
- Data register (sources, lawful basis, retention, access)
- Model and prompt register (versions, evaluation results)
- Change management log (what changed, why, approvals)
- Evaluation plan and test sets (what you test, how often)
- Monitoring and incident process (SLAs, escalation, postmortems)
- Third party and vendor assessments (LLM provider, annotation, hosting)
- Training and role guidance (who must know what)
Keep these artifacts close to delivery. If they live in a separate compliance tool that engineers never open, they rot.
Documentation artifacts buyers ask for
Beyond ISO language, buyers ask for concrete docs. Build them as reusable templates:
- AI feature spec with intended use and limitations
- System diagram showing data flows and trust boundaries
- Model card and data sheet summary
- Security controls summary: auth, logging, encryption, retention
- Evaluation report: test set, metrics, failure examples
- Incident response runbook for AI failures
Insight: The fastest procurement answers come from a product team that can point to a commit, a run, and a report. Not a slide deck.
Template: AI Feature Spec (minimum) - Purpose and user value - In scope users and out of scope users - Input types and prohibited inputs - Output types and prohibited outputs - Data sources and retention - Model choice and fallback behavior - Risk rating and mitigations - Evaluation metrics and thresholds - Monitoring signals and escalationWhat to store where
A simple storage split works well:
- Repo: specs, evaluation code, test sets, change logs
- Ticketing: risk intake, approvals, mitigation tasks
- Knowledge base: policies, runbooks, vendor summaries
The goal is traceability. A buyer asks “why this model?” and you can point to a decision record and an evaluation report.
Audit evidence checklist for AI products
What to have ready before the audit email landsKeep this checklist as a folder structure. If you can assemble it in 2 hours, you’re close.
- AI policy and scope
- AI system inventory with owners
- Risk register with last review dates
- AI feature specs for in scope products
- Data register: sources, classification, retention, access
- Vendor register: contracts, subprocessors, incident terms
- Model and prompt register with versions per release
- Evaluation plan with metrics and thresholds
- Test sets and latest evaluation reports
- Monitoring dashboards and alert definitions
- Incident log and postmortems
- Change management log for model, prompt, retrieval, and embedding updates
- Training records for required roles
Evidence quality test
- Can you trace one production incident to a mitigation change and a new evaluation run?
- Can you trace one release to model version, prompt version, and retrieval index version?
If you can’t, add traceability before you add more documents.
Controls that keep velocity
_> Enterprise grade controls without governance theater
Tiered approvals
Require explicit sign off only for high risk changes. Let low risk changes ship with automated checks and peer review.
Version traceability
Record model, prompt, embedding, and retrieval index versions per release so you can explain behavior changes.
Evaluation gates
Run a standard test set before release. Block deployments when metrics breach agreed thresholds.
Monitoring tied to users
Track task success, groundedness, refusal accuracy, and cost. Alert on trends, not anecdotes.
Vendor reassessment triggers
Recheck vendors when they change model behavior, subprocessors, or terms. Keep an exit path.
Data minimization defaults
Redact PII before indexing, avoid storing raw prompts, and enforce retention schedules.
Controls for data, models, vendors, and changes
Controls are where ISO 42001 becomes real. Not as a checklist, but as default behavior.
Governance as delivery loop
Controls that produce decisionsTreat ISO 42001 like a delivery system, not a policy folder. Build four visible layers: Intent → Controls → Execution → Evidence. What works
- One AI feature spec template in the repo (PM + Eng use the same doc).
- Risk intake creates a ticket, assigns an owner, and has an SLA.
- Approval gates only for high risk changes.
- CI checks for prompt, model, and retrieval changes.
- Monitoring tied to user impact and cost.
What fails
- Committees with no SLA. If you cannot ship a decision in under a week, teams route around it.
Example (delivery context): In our AI delivery work (for example, an AI driven exploratory data analysis tool built in 10 weeks using RAG), progress sped up after we made evidence a first class output: test set update, decision record, and release note tied to model and data versions each iteration.
Below is a practical control set grouped by what teams actually change.
Data controls
Common failure mode: teams treat “data” as a single blob. Auditors and attackers don’t.
Implement controls that answer:
- Who can access which datasets?
- Where does sensitive data appear in prompts, logs, and embeddings?
- How do you delete or expire it?
Minimum controls to ship:
- Dataset classification (public, internal, confidential, regulated)
- Access control tied to roles, not individuals
- Logging policy that avoids storing raw prompts with personal data
- Retention schedule for training data and RAG indexes
- Redaction for PII before indexing
Model controls
Common failure mode: model changes bypass review because “we didn’t change code.”
Controls that work:
- Version pinning for model and embeddings
- Release notes for prompt and retrieval changes
- Evaluation gate for high risk changes
- Rollback plan and fallback model
A simple model registry entry can be enough:
- Model name and provider
- Version or snapshot
- Intended tasks
- Known limitations
- Evaluation results and date
Vendor controls
Common failure mode: vendor risk is handled once, then forgotten.
Vendor controls to keep current:
- Data processing terms and subprocessor list
- Region and residency options
- Incident notification timelines
- Model training on your data (allowed or not)
- Change notification for model updates
If you use an LLM API, treat it like a critical dependency.
Change controls
The goal is not to slow changes. It’s to make changes explainable.
Use a tiered approach:
- Low risk changes: self approved with automated checks
- Medium risk changes: peer review plus evaluation run
- High risk changes: explicit approval plus canary release
Callout: In AI QA, regressions often come from prompt tweaks, retrieval index updates, or model version bumps. Put those changes under the same discipline as code.
Comparison table: control strength by risk
| Area | Low risk control | Medium risk control | High risk control |
|---|---|---|---|
| Data | Access roles documented | PII redaction verified | Formal DPIA style review and sign off |
| Model | Version pinned | Evaluation run on test set | Canary release plus rollback drill |
| Prompt and RAG | Peer review | Retrieval quality checks | Adversarial testing and safety gate |
| Vendor | Annual review | Contract and subprocessor check | Security review plus exit plan |
| Monitoring | Basic logs | Alert thresholds | 24 7 on call and incident SLAs |
A practical ISO 42001 checklist for controls
If you need a quick ISO 42001 checklist for product teams, start here:
- Do we have an inventory of AI systems and owners?
- Can we list every data source used for training, fine tuning, or retrieval?
- Are model, prompt, and embedding versions pinned and recorded per release?
- Do we have an evaluation set that matches real user tasks?
- Do we have thresholds that block high risk releases?
- Do we monitor groundedness, task success, and refusal behavior?
- Do we have an incident runbook for AI failures?
- Can we show vendor terms and data handling for each external model?
What AI audit readiness buys you
_> Outcomes you can measure
Faster procurement cycles
Reusable evidence reduces back and forth. Measure days to complete AI security questionnaires.
Fewer production regressions
Evaluation gates and version traceability reduce behavior surprises. Measure change failure rate for AI releases.
Cleaner incident handling
Runbooks and escalation rules shorten time to resolution. Measure MTTR for AI incidents.
More predictable delivery
Risk work becomes part of sprint planning, not a last minute blocker. Measure risk cycle time and backlog age.
Conclusion
ISO 42001 works when it behaves like a delivery system. It fails when it becomes a parallel bureaucracy.
If you want AI audit readiness without losing velocity, focus on three outcomes:
- Fast decisions: risk intake to decision in days, not months
- Reusable evidence: artifacts that answer procurement questions on demand
- Controlled change: model and data changes treated like production changes
Next steps you can do this week:
- Start an AI system inventory with owners and scope
- Implement the risk intake ticket and a weekly triage cadence
- Create the minimum artifact pack and store it where engineers work
- Add a change log for model, prompt, retrieval, and embedding updates
- Define 3 evaluation metrics and thresholds for your highest impact feature
Final insight: Governance that ships is not more process. It’s fewer, clearer decisions with proof attached.


