Introduction
AI features are easy to demo. Pricing AI features is where deals go to die.
You can ship an assistant, watch usage spike, then lose the enterprise deal because procurement cannot forecast spend. Or you can overcorrect with a flat fee and quietly eat inference costs until margins disappear.
This guide is about AI SaaS packaging that survives real procurement. Budgets. Approvals. Invoicing. And the not fun part: guardrails.
What we see in delivery work: teams that win long term treat pricing as a product surface. They instrument it, test it, and iterate like any other feature.
Insight: If a buyer cannot explain spend in one sentence, they will either block the purchase or force you into a discount that breaks your model.
You will get:
- A decision matrix for usage based pricing SaaS in AI heavy products
- A usage metric design checklist
- A margin model template that maps costs to pricing levers
- Packaging examples: add on vs embedded vs premium tier
A quick proof point
In our experience shipping production ready AI features, the cost curve is not theoretical. In one AI assistant style system we built and evaluated with structured tracing and datasets, small prompt and retrieval changes shifted both answer quality and token usage. That is why pricing and QA need the same discipline.
And on the delivery side, we have shipped products fast when the scope is clear. For example, a luxury retail Shopify build for Miraflora Wagyu shipped in 4 weeks, and an AI driven exploratory data analysis tool (LEDA) shipped in 10 weeks using RAG patterns. Speed is possible. Pricing still has to hold up after the demo.
_> What buyers ask for
The numbers that show up in enterprise pricing reviews
Choose your pricing model
There are three core models that show up in AI SaaS. Most teams pick based on what competitors do. Better: pick based on what you can meter, what you can control, and what procurement can approve.
Seat pricing
Seat pricing is simple. It also hides the AI cost problem until usage concentrates in a few power users.
Good fit when:
- Value scales with number of users, not volume of AI work
- AI is supportive, not the primary workload driver
- You need predictable budgets for enterprise rollouts
Failure modes:
- A few users generate most of the inference cost
- Buyers demand unlimited usage per seat, then run batch jobs through the UI
Usage pricing
Usage based pricing SaaS works when the unit maps to cost and value. But only if you design the metric well.
Good fit when:
- Workload volume varies a lot across customers
- You can measure usage with low dispute risk
- Your gross margin is sensitive to tokens, retrieval, or tool calls
Failure modes:
- Meter is abstract, buyers do not trust it
- Bills surprise finance teams, renewals get blocked
Outcome based pricing
Outcome based pricing is attractive because it aligns incentives. It is also the hardest to implement without long sales cycles and contract complexity.
Good fit when:
- You can define outcomes with clean attribution
- You control enough of the workflow to influence results
- You can survive a longer procurement and legal process
Failure modes:
- Attribution disputes
- Outcomes depend on customer behavior you cannot control
Key Stat: In AI products, output quality can drift without code changes. If outcomes are your price basis, you need instrumentation and QA that can explain changes, not just detect them.
Here is a practical comparison table you can use in pricing reviews:
| Model | Buyer predictability | Seller margin protection | Metering complexity | Procurement friction | Best for |
|---|---|---|---|---|---|
| Seat | High | Low to medium | Low | Low | Collaboration tools, workflow SaaS |
| Usage | Medium | High | Medium to high | Medium | APIs, automations, AI heavy workflows |
| Outcome | Medium to low | Medium | High | High | Revenue impact workflows with clear attribution |
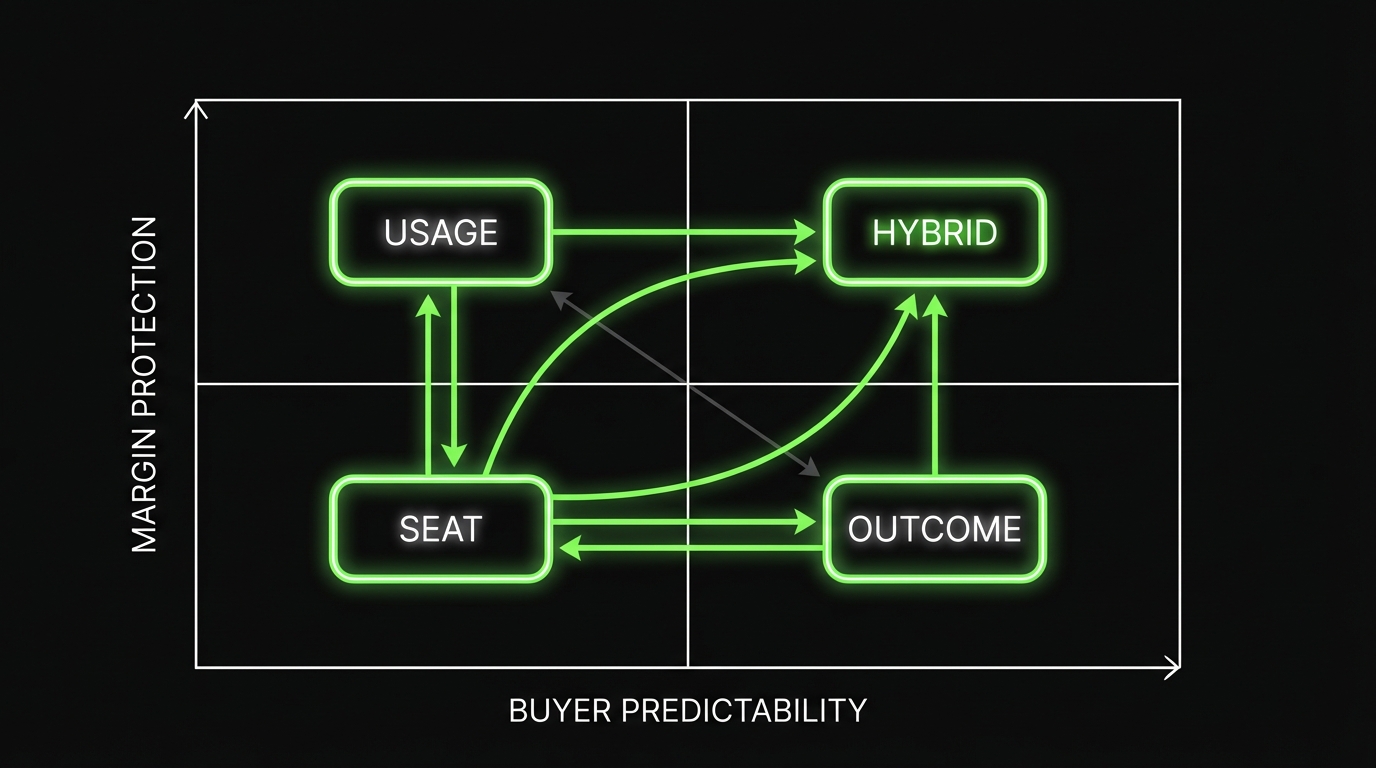
Pricing decision matrix for AI heavy SaaS
Use this as a starting point. Score each from 1 to 5.
| Question | Why it matters | Seat | Usage | Outcome |
|---|---|---|---|---|
| Can we meter it reliably? | Disputes kill renewals | 5 | 3 | 2 |
| Does cost scale with volume? | Protects gross margin | 2 | 5 | 3 |
| Can procurement forecast spend? | Budgets and approvals | 5 | 3 | 2 |
| Can we explain it in 30 seconds? | Reduces cycle time | 5 | 3 | 2 |
| Can we attribute value? | Needed for outcomes | 2 | 3 | 5 |
How to use it:
- Score your product today, not your future vision.
- If usage wins, design the meter and guardrails before you publish pricing.
- If outcome wins, start with a pilot contract and a backup pricing floor.
Common packaging mistakes
- Pricing tokens directly to business buyers
- Bundling expensive models into low tiers with no guardrails
- Calling something outcome based without clean attribution
- Hiding limits until the invoice arrives
- Treating usage reporting as a future improvement
Hybrid packaging workflow
_> A simple way to design plans without guessing
→ Scroll to see all steps
Hybrid packaging that works
Most AI products land on a hybrid. Not because it is trendy. Because it gives procurement predictability and gives you margin protection.
Guardrails at the boundary
Entitlements keep pricing honestAI cost spikes come in bursts (large documents, batch jobs, tool call loops). Treat guardrails as product, not legal text. Ship these first:
- Hard limits (monthly credits, max docs, max tool runs) + soft warnings (80%, 90%, 100%).
- Throttles or queues for batch workloads.
- Fair use language backed by telemetry.
Engineering rule: enforce limits at the API boundary, not only the UI. Log metering events with customer id, metric, amount, and model version so finance disputes are resolvable. Quality meets cost: a prompt change that increases tokens by 30% is a regression even if answers look fine. Track tokens per task and cost per successful outcome.
A solid hybrid has two layers:
- Predictable base: seats, platform fee, or tier
- Variable layer: usage packs, overages, or add ons tied to cost drivers
What makes hybrid fail is ambiguity. If buyers feel like you can change the rules mid quarter, they will push for unlimited terms.
Insight: Hybrid pricing only works when the base fee covers fixed costs and the variable fee covers the part you cannot control.
Common hybrid patterns:
- Seats + included AI credits + overage
- Platform fee + usage based pricing SaaS meter
- Tiered plan + paid add on for advanced AI features
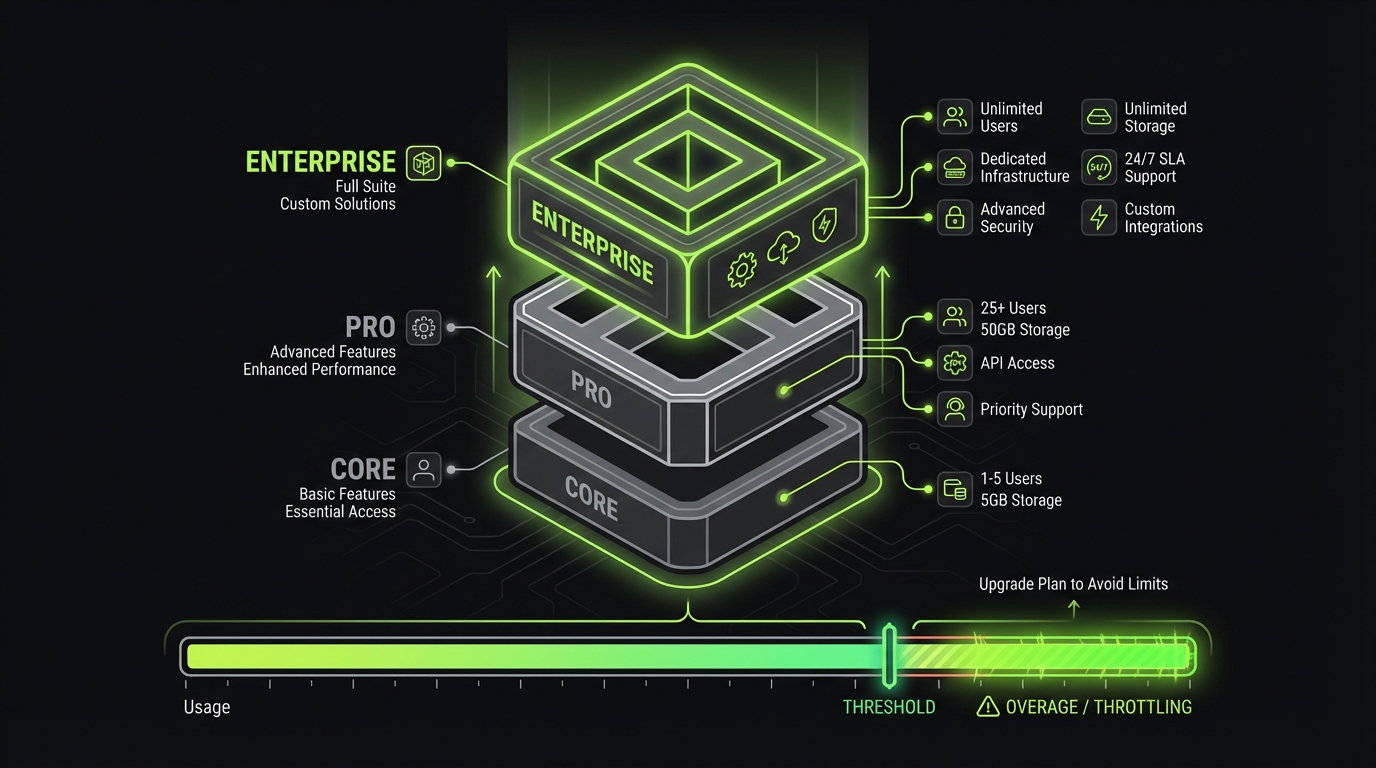
Packaging examples: add on vs embedded vs premium tier
You have three clean options. Pick one per feature category, not per feature.
- Embedded in every tier
- Use for table stakes features that reduce churn
- Example: basic AI search, simple summarization
- Risk: you pay for heavy users unless you set guardrails
- Add on
- Use when value is optional or departmental
- Example: compliance mode, additional knowledge bases, advanced evaluation reports
- Benefit: procurement can approve as a separate line item
- Premium tier
- Use when AI changes the product category
- Example: analyst copilot that executes workflows, not just answers questions
- Benefit: simpler invoice, clearer ROI story
A practical rule:
- If the feature changes who buys, put it in a premium tier.
- If it changes how much it costs you, make it an add on or usage metered.
- If it is required to stay competitive, embed it but cap it.
Entitlements you can sell
_> Clear limits that reduce disputes
Included AI credits
A simple allowance per workspace or per seat. Buyers can budget it. You can model it.
Model tier controls
Default to a cheaper model, allow upgrades for specific workflows or teams.
Knowledge base caps
Limit sources, documents, or embedding volume. Offer add ons for expansion.
Admin spend caps
Hard stops or throttles after a budget threshold. Reduces surprise invoices.
Usage exports
CSV or API exports that match invoice line items. Makes finance happy.
Audit ready logs
Metering events tied to feature, model version, and workspace. Useful for billing and QA.
Entitlements and guardrails
Guardrails are not a dark pattern. They are how you keep pricing honest.
Model choice tradeoffs
Metering vs approvals vs marginUse the comparison table as a decision gate, not a slide.
- Seat pricing: predictable budgets, easier approvals. Fails when a few power users drive most inference cost. Mitigation: per workspace caps or included credits per seat.
- Usage pricing: best margin protection when the unit maps to cost and value. Fails when the meter is abstract and bills surprise finance. Mitigation: usage packs, alerts at 80% and 90%, and a dispute resistant meter.
- Outcome pricing: aligns incentives but adds attribution disputes and longer legal cycles. Only use it when you can instrument quality drift and explain changes, not just detect them.
Metric to track: % of customers with usage concentration (top 10% users generating >50% of AI cost). That tells you if seat only pricing will break.
In AI, cost and risk spike in bursts:
- One user pastes a 200 page PDF
- A team runs nightly batch summarization
- A prompt injection attempt triggers tool calls
So you need entitlements (what is included) and guardrails (what happens at the edge).
Guardrails you can ship without breaking UX:
- Hard limits: monthly credits, max documents, max tool runs
- Soft limits: warnings at 80%, 90%, 100%
- Throttles: slower processing after threshold
- Queues: batch jobs run in off peak windows
- Fair use: language that covers abuse patterns, backed by telemetry
Key Stat: In AI QA work, we treat cost as a test dimension alongside correctness. A prompt change that increases tokens by 30% is a regression even if answers look fine.
The key is to make limits visible:
- Show remaining credits in product
- Provide admin controls per workspace
- Export usage reports for finance
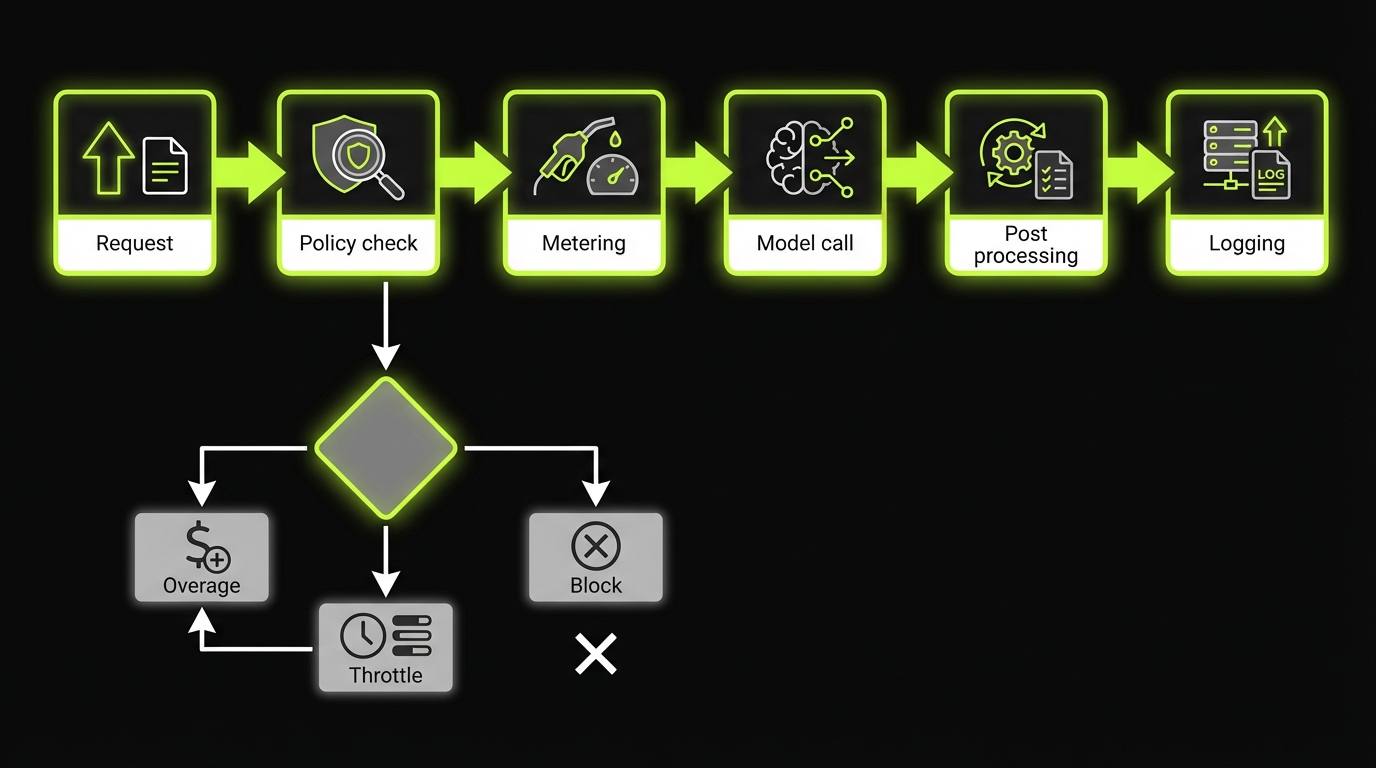
Code wise, guardrails should be enforceable at the API boundary, not only in the UI. A minimal pattern:
if usage.monthly_credits_used >= plan.included_credits:
if plan.overage_enabled:
bill_overage(request.estimated_cost)
else:
throttle_or_block("Credit limit reached")
log_metering_event(customer_id, metric, amount, model_version)
That last line matters. If you cannot tie spend to model version and feature, you cannot debug margin.
Usage metric design: what to meter and why
Bad meters create disputes. Good meters create trust.
Start with the question: what is the buyer actually buying?
- Time saved
- Volume processed
- Risk reduced
- Decisions improved
Then choose a meter that is:
- Auditable: customer can reconcile it
- Predictable: does not jump unexpectedly
- Cost aligned: tracks your main cost drivers
Common AI meters and when they work:
- Tokens: best for API first products, worst for procurement discussions
- Documents processed: good for back office workflows
- Tool calls: good when tools are the expensive part
- Seats with AI credits: good for adoption, needs caps
- Workflows executed: good when AI triggers multi step automation
A quick checklist:
- Can a customer estimate next month within 20%?
- Can you explain the meter without mentioning tokens?
- Can support resolve a billing ticket with logs?
- Can you separate human usage from automation usage?
Procurement ready pricing checklist
Use this before you publish plans- Can a buyer forecast next quarter spend within 20%?
- Do you offer a base subscription line item?
- Do admins get spend caps, alerts, and exports?
- Is the usage unit defined in one sentence?
- Do overages have a hard stop option (throttle or block)?
- Can support reconcile a bill from logs within 15 minutes?
- Do contracts name the meter and the rate?
- Is there a documented fair use policy tied to telemetry?
Why hybrid wins in enterprise
_> Predictability plus margin protection
Shorter approval cycles
A stable base fee fits budgeting. Variable usage is constrained and explainable.
Fewer billing disputes
Clear entitlements and visible usage reduce surprise and improve renewal trust.
Better gross margin control
Overages and model tiering protect you from power users and batch workloads.
Cleaner expansion paths
Add ons map to departments and use cases, not awkward plan jumps.
Procurement friendly constructs
Procurement does not hate AI. Procurement hates surprises.
Procurement one sentence test
If they cannot explain spend, you loseRule: If a buyer cannot explain spend in one sentence, procurement will block it or force a discount. Make it pass:
- Pick a meter finance can forecast (seats, platform fee, or a simple usage unit).
- Show the spend equation upfront (base + included + overage).
- Provide an admin view with remaining credits and an exportable usage report.
What to measure (hypothesis): time to approval and discount rate before vs after adding a forecastable spend summary in the quote and invoice.
If you want enterprise deals, design packaging for:
- Annual budgets
- Approval thresholds
- Invoice line item clarity
- Predictable renewal terms
What works in practice:
- Annual commit with monthly true up
- Prepaid usage packs that expire annually
- Budget caps with automatic throttling instead of runaway overages
- Separate line items for regulated features (audit logs, retention, VPC)
What tends to get blocked:
- Unlimited usage with vague fair use
- Overage only models with no spend cap
- Meters that cannot be reconciled
Insight: The fastest way to shorten security and procurement review is to make spend controls an admin feature, not a contract promise.
A procurement ready pricing page usually includes:
- Clear definition of the usage unit
- Example invoice math
- Overage behavior
- Spend caps and alerts
- Data retention and compliance options
And yes, invoicing matters. Finance teams want:
- A stable base subscription line
- A separate usage line with quantity and rate
- A usage report export that matches the invoice
In our delivery work on enterprise grade products, we see the same pattern: teams that add admin grade reporting early avoid months of back and forth later. This is true for AI features too, especially when regulated industries ask for compliance by design.
Margin model template: costs to pricing levers
You do not need a perfect finance model. You need a model that catches bad packaging before customers do.
Map your unit economics like this:
| Cost driver | What moves it | How to measure | Pricing lever |
|---|---|---|---|
| Model inference | Tokens, context size, model choice | tokens per request, cost per 1K tokens | included credits, overage rate, model tier |
| Retrieval | Embedding volume, index size, queries | queries per user, vector DB costs | knowledge base limits, add on for extra sources |
| Tool calls | External APIs, compute jobs | tool calls per workflow | workflow packs, tool call meter |
| Human review | Escalations, QA sampling | reviews per 100 outputs | premium tier, compliance add on |
| Support | Billing tickets, prompt issues | tickets per 100 users | better metering UX, admin reporting |
Then set guardrails:
- Pick a target gross margin per tier.
- Define included usage that keeps you above it for the 80th percentile customer.
- Price overages to protect the 95th percentile.
If you do not have data yet, label it.
- Hypothesis: average user runs 30 AI actions per week.
- Measure: actions per user per week, p50, p80, p95.
- Decide: include p80, monetize above.
Conclusion
AI SaaS pricing is not about cleverness. It is about clarity under pressure.
If you want packaging that survives procurement, build for three things:
- Predictability for budgets
- Control for admins
- Protection for margins
A practical next step list:
- Audit your current plans: where can spend surprise a buyer?
- Pick one primary meter and one backup (for disputes).
- Add entitlements and guardrails at the API layer.
- Ship usage reporting that matches invoices.
- Define ROI KPIs per tier and instrument them.
Final takeaway: If you cannot explain value and spend per tier with credible KPIs, you do not have packaging yet. You have a price list.
If you are building AI features now, treat pricing like QA. Instrument it. Test it. Iterate it. That is how it holds up after the first demo.
Measuring ROI per tier with credible KPIs
Procurement will ask, "What do we get for this tier?" Your answer needs numbers.
Pick 3 to 5 KPIs per tier. Keep them hard to game.
Examples that work:
- Time to task completion: minutes saved per workflow
- Task success rate: percent of requests completed without rework
- Deflection rate: percent of tickets or analyst requests avoided
- Accuracy with sources: percent of answers supported by retrieved citations
- Cost per outcome: cost per report, per case resolved, per workflow executed
Tie each KPI to a tier promise:
- Core: faster basics (time saved)
- Pro: higher throughput (workflows executed, deflection)
- Enterprise: risk and governance (accuracy with sources, audit coverage)
And be honest about what you can prove today.
- If you do not have baselines, run a 2 week measurement period.
- If quality varies, report p50 and p90, not only averages.


