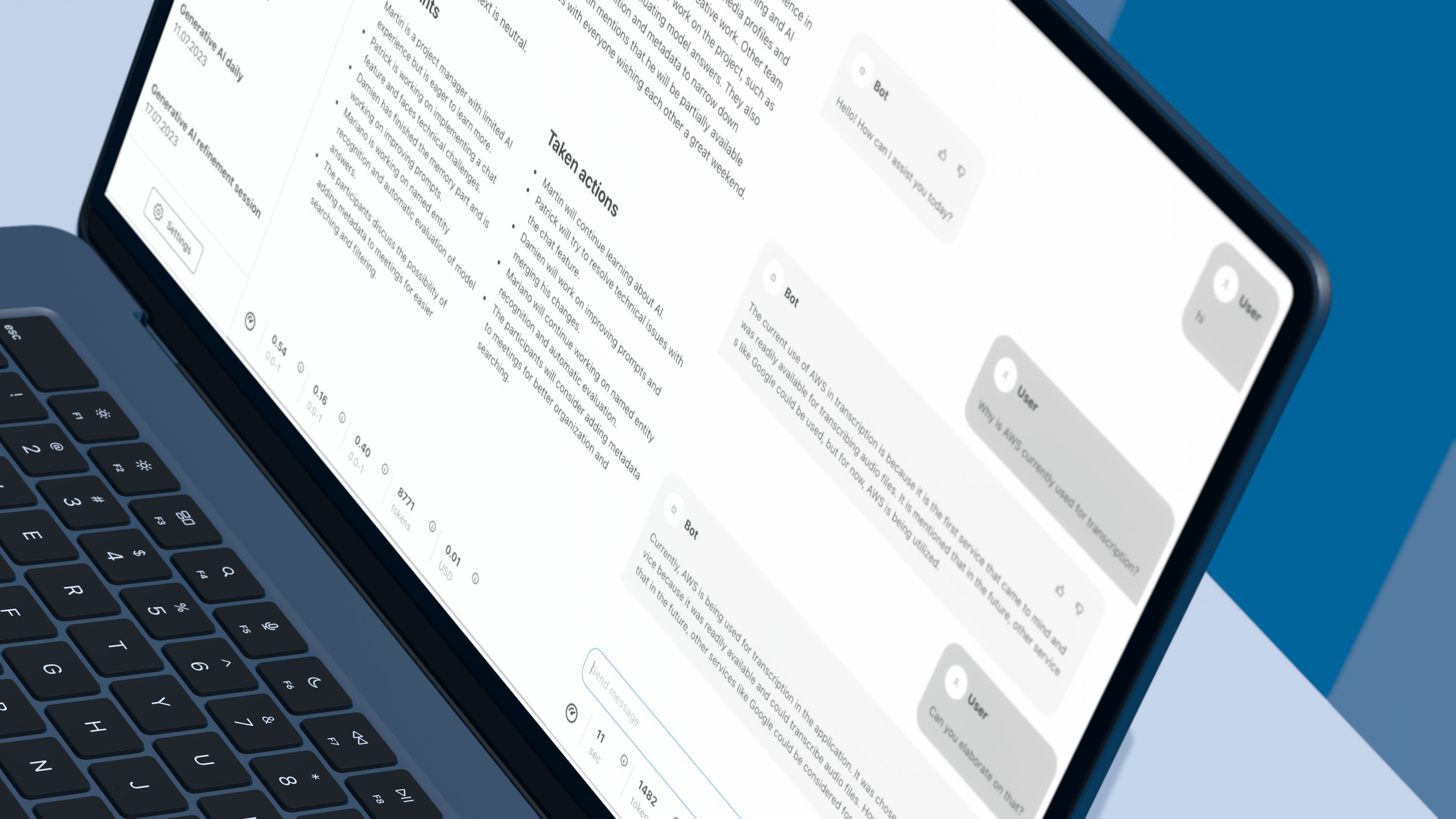
In just three weeks, our team transformed the concept into reality, achieving milestones along the way. We implemented a real-time Speech-To-Text transcription system that could transcribe spoken words with an impressive delay of around 1 second. This quick turnaround ensured that users experienced a smooth and natural conversation with the avatar.
To enhance the avatar's responsiveness, we integrated Claude 3 Haiku, optimized for speed and tasks like instant customer support, with GPT-4's advanced reasoning capabilities. This powerful combination allowed the avatar to provide quick and intelligent answers, making the interaction more engaging and informative. Our team achieved real-time Text-To-Speech audio streaming with a minimal delay of approximately 0.
This swift response time was crucial in maintaining the conversational flow, ensuring that users felt as though they were speaking with a live person. By introducing a filler sentence approach (described in the process section), we effectively bridged the gap while the system processed user queries. This tactic brought the overall latency feeling down to around 1.
5 seconds, enhancing the user experience by making the avatar's responses seem more immediate. As the client is pleased with our POC results, we are not stopping and are continuing this exciting journey. On our roadmap are the next challenges: While effective, filler sentences can't be used constantly.
We are exploring additional UX strategies to further reduce perceived latency. We are working on adding conversation memory, knowledge grounding, and moderation capabilities to provide more contextually relevant and grounded responses. Identifying a scalable and resilient audio streaming platform that ensures high audio quality remains our priority.
Sounds interesting? Stay tuned as we will soon launch the next case study with the final project outcome!