
We invite you to the next stop on our journey through the process of creating Mobegí - our innovative AI conversational assistant designed to streamline access to company knowledge. The fourth article from the series delves into the dual structure of Mobegí's brain - pipelines for structured query processing and agents for dynamic reasoning.
We'll explore our approach to handling user queries, from simple inputs to complex conversations, and our innovative solutions for anonymization and maintaining conversational memory. We'll also highlight key features like prompt injection prevention and sentiment analysis, showcasing our commitment to creating a secure and empathetic AI assistant.
Continue to uncover the insights and innovations behind Mobegí's development.
Conversing with Mobegí
Within our brain module, we currently incorporate two fundamental components: pipelines and agents.
A pipeline, which is essentially a LangChain chain, unfolds as a sequential series of steps, each defined by a distinct input and output schema. These pipelines exhibit composability, given that the pipeline itself adheres to an input and output schema, allowing for flexibility in length and complexity.
An LLM agent operates on a different paradigm. Here, we provide it with a toolkit and a reasoning approach implementation, typically articulated as a chain of thoughts. The agent, running autonomously, deduces the logic based on the tools and methods provided.
Upon experimenting with the agentic approach, we opted for maintaining the core process of the application as controllable and straightforward as possible and chose to implement it as a pipeline. That said, as a note for the reader, we are actively working on applying an agentic approach specifically to the retrieval step, which we'll elaborate on in more detail as we progress.
For a better understanding of the process, we present as an example the query:
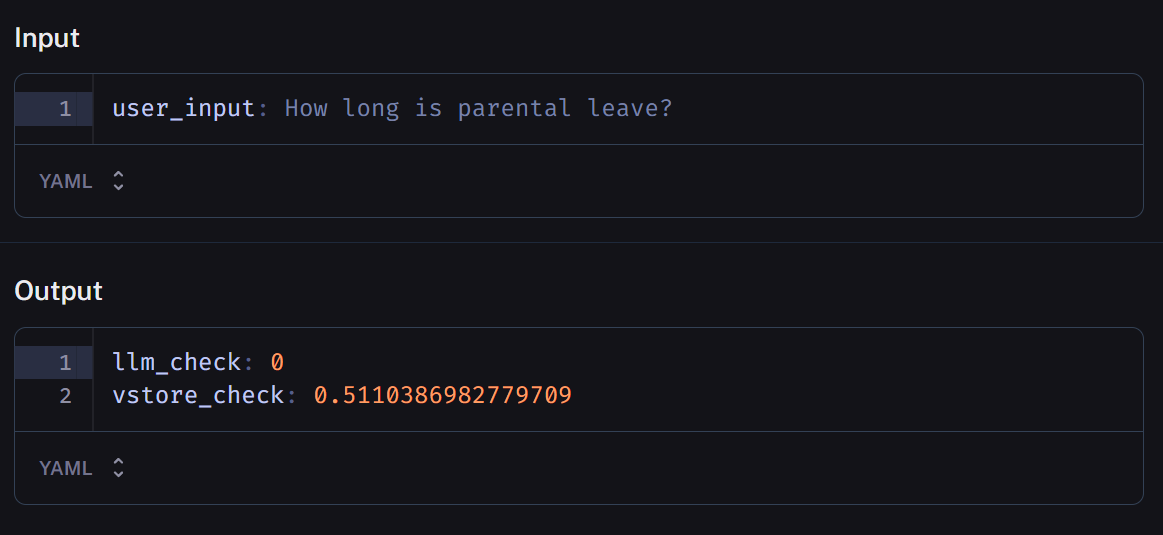
“How long is parental leave?”And then follow all the evolution of the information through the pipeline steps.
Query
For the current version, we assumed only a simple query as an input – a question from the user that we did not feel the need to break down further. We were aware of several approaches to handle more complex queries, such as step back and query rewrite techniques offered by tools like LangChain. However, we decided to focus first on implementing a solid evaluation framework before exploring those more advanced question-handling capabilities.

Input anonymization
As the user prompt itself could contain sensitive information, the first step must be its anonymization. From the field:
knowledge_configuration_data_snapshot_idin our branch configuration, we can retrieve information about the current knowledge data version and its source, the world data version. The anonymizer map will be under:
ROOT/data/anonymizer_map/[world_version_id]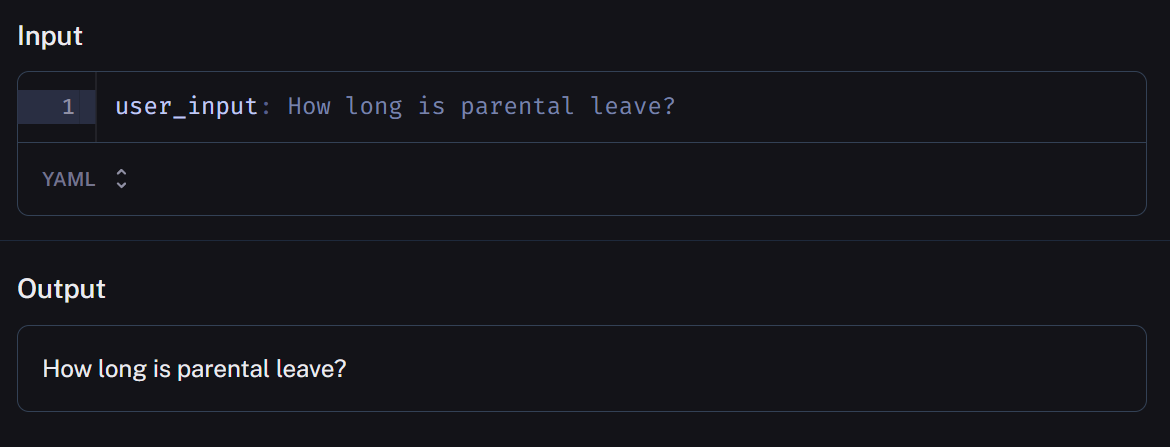
Conversation memory
In human conversations, we make implicit assumptions of shared knowledge and a building common ground that develops throughout the dialogue. However, LLMs don't come pre-equipped with either of these aspects, and this is where RAG steps in to fill the void.
We explored a few options for enabling conversational memory:
- Buffer Window Memory: which maintains a list of interactions throughout the conversation, considering only the last K interactions. It proves beneficial for sustaining a sliding window of the most recent interactions, preventing the buffer from ballooning in size.
- Entity Memory: which captures information about entities, utilizing an LLM to extract and accumulate knowledge about each entity over time.
The ultimate goal is finding the right balance between relevance and size when determining what context to retain.
Our choice rested on Summary Memory and its implementation in LangChain. This type of memory generates a condensed summary of the conversation as it unfolds. This approach proved to be the best compromise for distilling information over time. The conversation is stored in Firestore, under:
conversations/[conversation_id]Within the Slack integration, we also associated the conversation_id with a Slack message thread. This allowed us to implicitly determine when a conversation was closed based on the thread rather than requiring the user to tell us explicitly.

Prompt injection prevention
Prompt hacking can manifest in various forms, ranging from subtle manipulations to sophisticated linguistic constructs that exploit model vulnerabilities. Crafting a comprehensive defense against every conceivable manipulation would require continuous adaptation and an intricate understanding of the intricate ways in which users might exploit language models.
Therefore, we've pragmatically opted to focus on addressing simpler attack patterns, implementing a double pass defense.
In the initial pass, we task an LLM with scrutinizing the prompt for signs of malicious intent. Specifically, we flag prompts that exhibit nonsensical English constructs or attempt to coerce actions, such as disregarding prior instructions. The LLM grades these prompts on a scale from 0 to 1, with 1 indicating a high likelihood of malicious content. If the assigned value surpasses a predefined threshold, we trigger an exception.
If the prompt passes the first check, we move on to the second test, where we compare it against a vector store containing known prompt hack messages. During this phase, we assess semantic similarity distances. If the average distance from the first 5 results falls below a configurable threshold, we again raise an exception.
Importantly, both thresholds employed in this double-pass check are fully configurable through the Skillset configuration data.
For more information about the topic, there is a section entirely dedicated to safety in LangChain documentation.
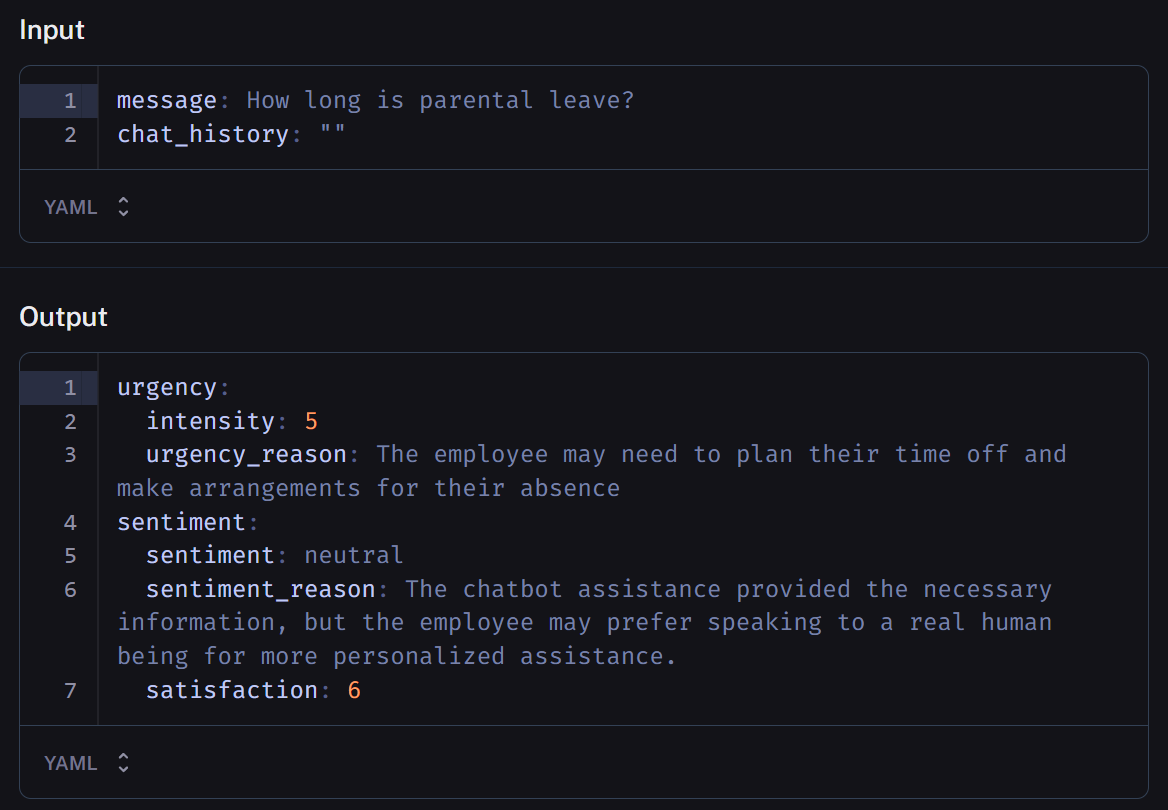
Sentiment and urgency analysis
In this step, we use the same LLM – instructing it differently – to detect the user's sense of urgency and satisfaction. Originally conceived with a support use case in mind, this step would have served a dual purpose.
First, to allow us to monitor the progression of these sentiments throughout the conversation, offering valuable insights into user dynamics. Additionally, helping the system "understand" when it's opportune to route a query to a human.
As in other aspects of the development process, we pushed in a direction with the main purpose of gathering knowledge, even as, in this case, the solution doesn’t exactly fit a need. Ultimately, we repurposed the sentiment decoration by leveraging it to generate a preliminary response.
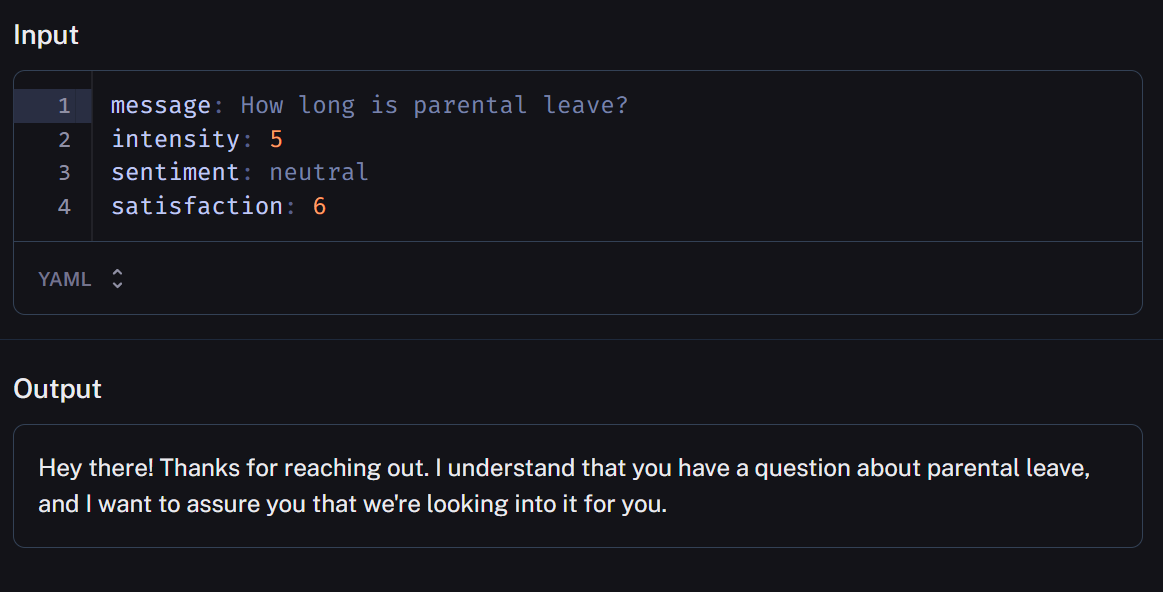
Initial response
We used a distinct LLM and instructed it to give reassurance and descale urgency when needed by analyzing the result of the previous step.
You're a helpful company buddy whom people ask questions about the company and its procedures,
don't be formal, act as a colleague.
Your task is to give a brief message to reassure the user that you are working on his issue.Our intent was two-fold: to buy time during response retrieval and, simultaneously, to explore the boundaries of empathy in a text generator.
We were aware it was presumptuous of us, yet it didn't result in a complete failure. While acknowledging the need for refinement and fine-tuning, we found that, especially in the initial response of a multi-turn conversation, the approach partially achieves its intended goal.
Retrieval
Our current retrieval process is straightforward.
We utilize Sentence Window Retrieval, aligned with our approach for ingesting data which, similarly to techniques like Parent Document Retrieval, lets us:
- search for small enough documents so that embeddings accurately capture meaning too long and the vector representation loses fidelity,
- retrieve long enough snippets to retain contextual meaning around the small documents above.
Some of these steps are handled behind the scenes by the LangChain retriever and the Chroma vector store, but we'll articulate each one for clarity:
Retriever input
We pass the context built so far, a condensed version of the query and the conversation history, to our retriever.
Vector store retrieval
Using an Approximate Nearest Neighbours (ANN) algorithm with cosine similarity as distance measurement, Chroma retrieves a large list of relevant documents, by default 25 matches.
If you want to know more about ANN and semantic search, “Semantic Search ANN” by Jun Xie provides an excellent and accessible reference.
An important note is that documents are returned along with ingestion metadata at this stage. We leverage this to swap out individual sentences with the full section of related text that was originally indexed.

Reranking
The list is then reordered using the LangChain implementation of a technique known as Maximal Marginal Relevance (MMR).
Relying solely on similarity scores can yield redundant results.
MMR helps address this by balancing relevance to the original query with diversity across the ranked items. It aims to minimize duplicated content while preserving the relevance of top-matching documents.
If you want to have more details, here is the link to the original paper.
Outcome
Finally, the top n results are selected, where n is specified in the retriever configuration parameters. These top-ranking document snippets are joined together as a single block of text, separated by a simple delimiter.
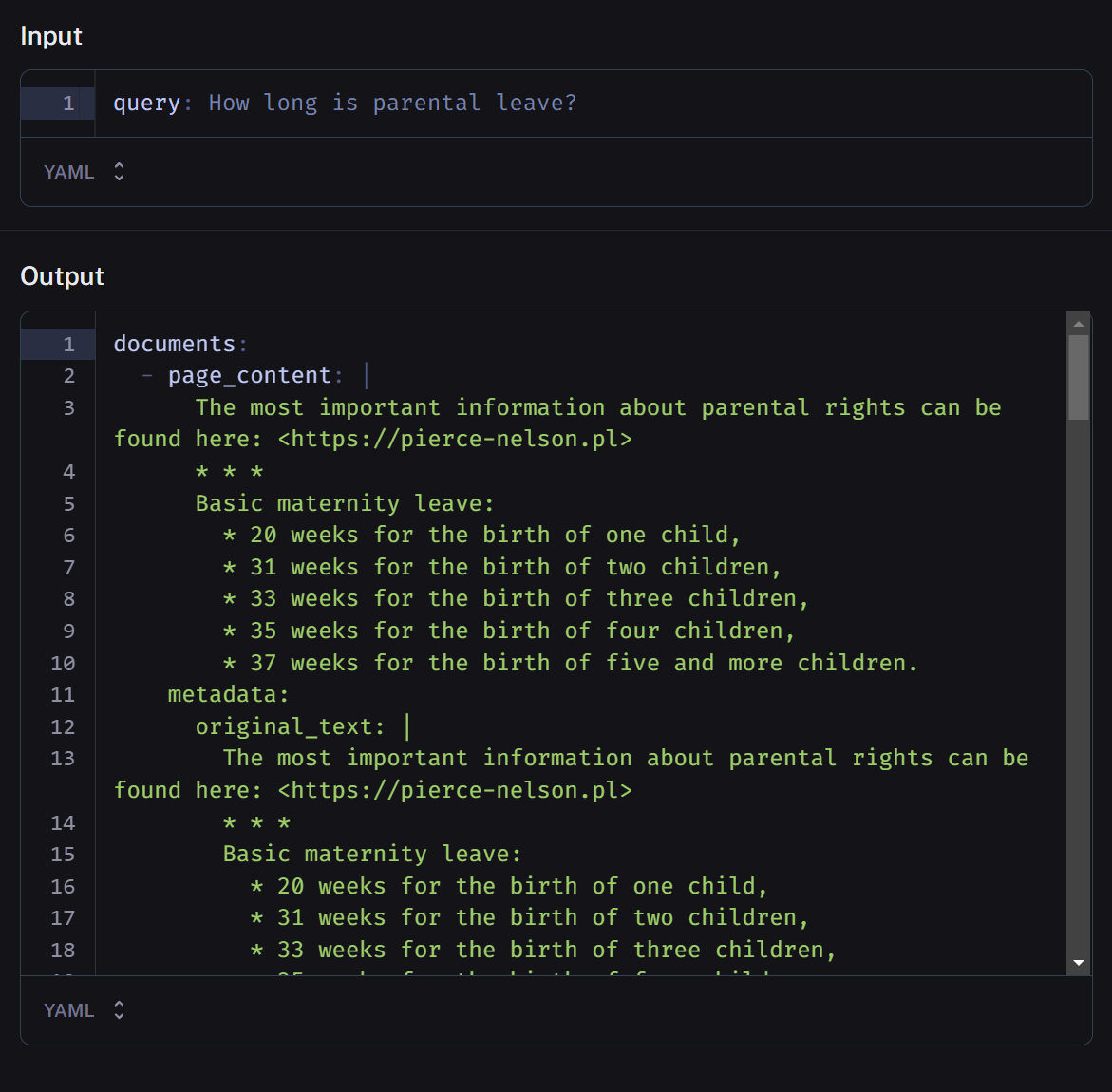
Response
The consolidated retrieval output is then passed to the generator, together with the condensed context we used as retrieval input.
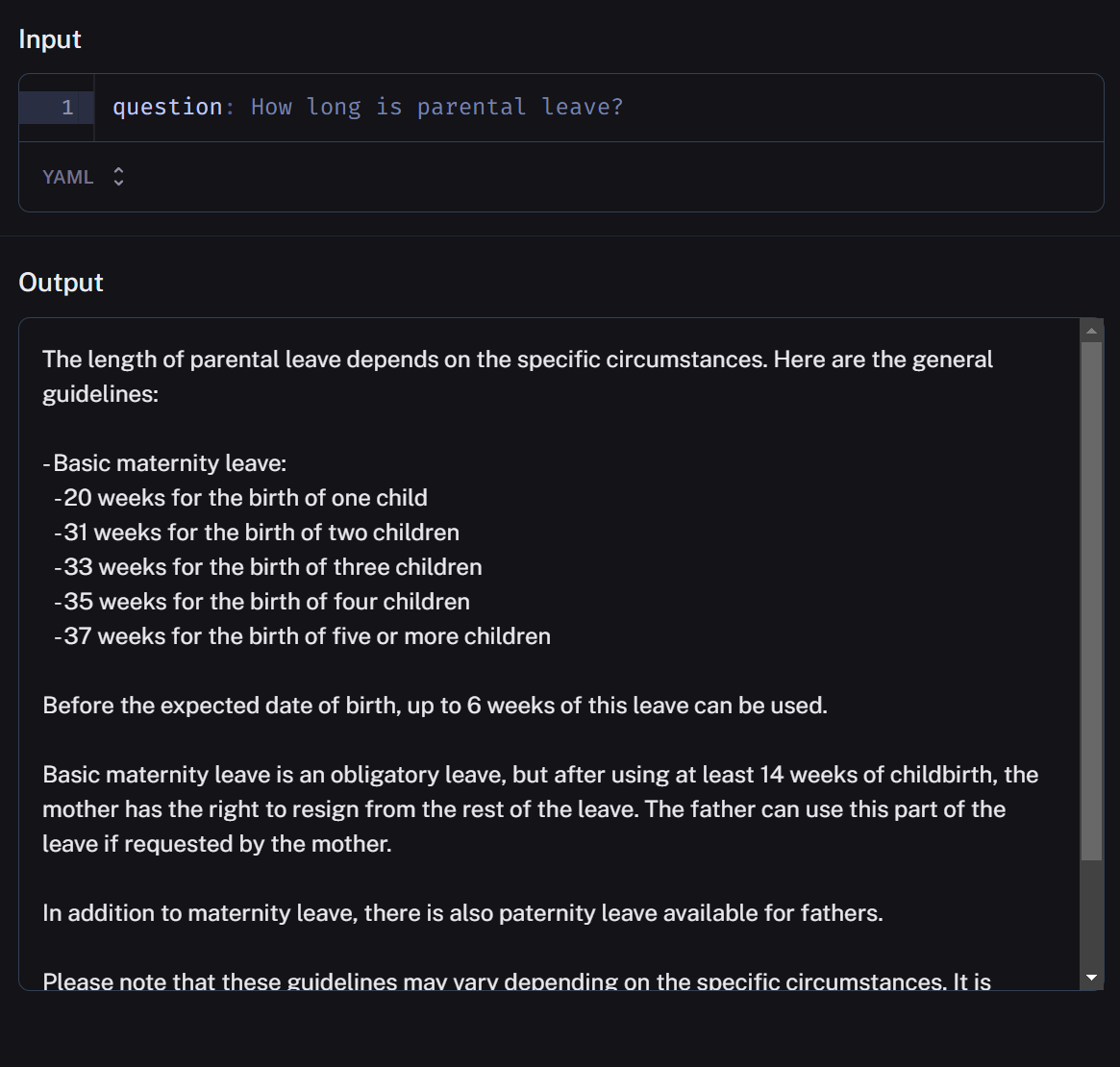
Output deanonymization
As a final step before presenting the response to the user, we deanonymize any sensitive entities that were replaced earlier in the input preprocessing. Once again, the anonymizer map is under:
ROOT/data/anonymizer_map/[world_version_id]This time, we use it to switch the placeholders back to the real entity names or values.
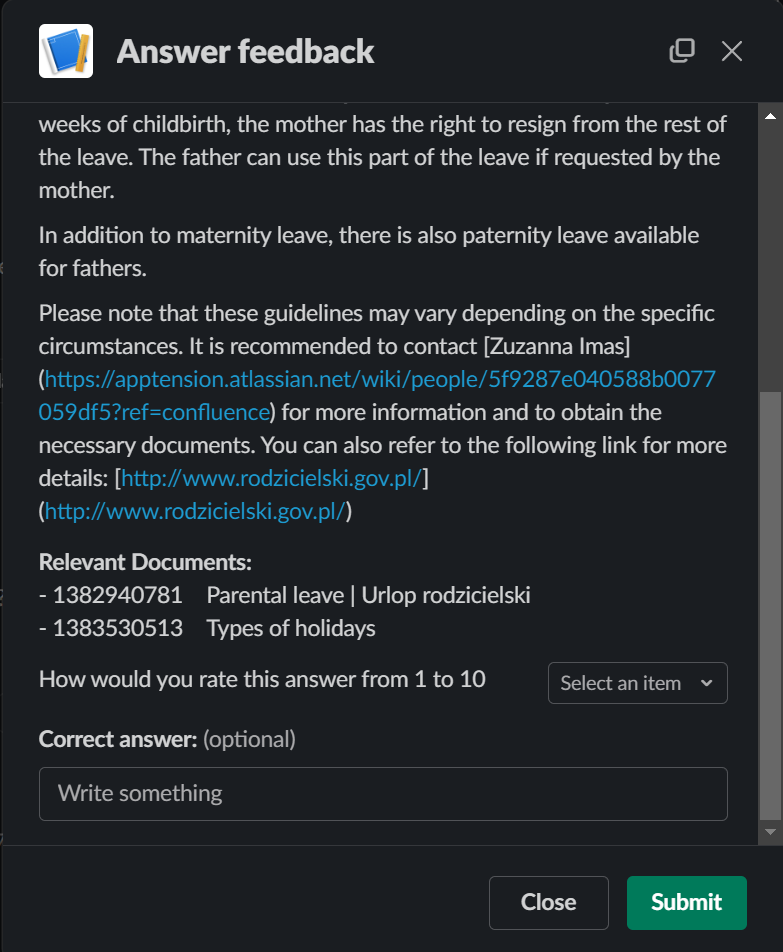
Feedback widget
We collect this directly within a widget below each response. In addition to scoring the answer on a 1-10 scale, users can leave short freeform commentary, especially around any perceived issues.
In case of negative ratings, we wanted them to be able to note retrieval false positives.
That’s why we display the source Confluence pages that were added as metadata at ingestion time. By showing users this information alongside the final answer, they can provide better-informed quality feedback, which accumulates over time into our evaluation framework.
A note on embeddings fine-tuning
Let’s step back a few months. In the first part of our exploration, we had taken into consideration fine-tuning as an alternative to RAG, focusing specifically on full LLM fine-tuning. After investigating recent literature comparing the two approaches (see "RAG vs Fine-tuning - Which Is the Best Tool to Boost Your LLM Application?" by Heiko Hotz, which we found to be an excellent and worthwhile read on the topic), we concluded that RAG was the better fit for our needs.
Fast forwarding to September, we came across an intriguing LLamaIndex blog post about achieving 5-10% retrieval performance gains by fine-tuning just the embedding model rather than the full LLM.
This made sense - off-the-shelf embeddings may occupy a latent space aligned to their pre-training objective rather than our specific retrieval needs.
Fine-tuning essentially transforms the embeddings into a new latent space optimized for retrieval with our data and query distribution. This can lead to marginal retrieval improvements that compound into more capable RAG systems.
And, as a bonus – you only need to transform the query embeddings as input to your unchanged indexed documents!
When we first tested this, we did not have a proper evaluation infrastructure to quantify gains. But now that we are equipped with it, revisiting embedding fine-tuning could help further boost performance. It remains on our roadmap for the near future.

Coming next
Thank you for exploring the architecture of our conversational question-answering system! We covered critical pipeline elements like input anonymization, retrieval augmentation, and response generation.
Next, we will outline how we generate synthetic datasets and leverage the Langsmith platform from LangChain as a robust test and evaluation framework.