
In the second part, we're continuing our fascinating journey with Mobegí, an AI-driven solution designed to automate and streamline employee inquiries in office operations. Utilizing modern language models and retrieval-augmented generation (RAG), it offers a Slack bot interface to handle repetitive questions efficiently and direct complex queries to human staff.
We will dive into the heart of Mobegí's architecture, which emphasizes flexibility and adaptability. It features a modular, configurable framework that can evolve alongside AI advancements. The system is divided into key modules for different functionalities, from data handling to user interaction. This design ensures Mobegí remains agile, responsive, and up-to-date, showcasing an innovative approach to integrating AI in workplace operations.
Continue reading to fully grasp Mobegí's architecture, data versioning, and configuration.
Foundations
When designing Mobegí's architecture, we aimed for flexibility beyond the initial scope to support future use cases. Perfection was never the goal. Given the rapid evolution of AI generative capabilities, it was malleability that we hoped to leverage.
Modularity allows us to maintain components discretely as research precipitates new best practices and incrementally build a reusable framework. At the same time, it gives us the flexibility to adjust architectural plans during that ongoing conversation between initial design thinking and practical implementation learnings.
Composable over complicated. Configurable over customized.
Configurability and comparability intrinsically link. Code encapsulates the precise tuning parameters-data sources, filtering thresholds, and routing rules. By exposing all dials and representing system orchestration as a declarative configuration file, we essentially redefine the application as composable data.
App architecture
Even if Generative AI is a relatively fresh domain, we knew there were already a few promising projects/frameworks we may need as dependencies. Microsoft offered Semantic Kernel and the open-source community developed LangChain and LlamaIndex, just to name a few. Each solution defined its own terminology and concepts.
With this in mind, we designed our architecture to provide abstraction, organizing components by responsibilities rather than specific implementations. Our goal was to remain agnostic of any main dependency (spoiler alert: we eventually chose LangChain) - both terminology and concepts.
Our retriever component could interchangeably leverage a "connector" from Semantic Kernel or a "chain" from LangChain without redefining its name or purpose in our architecture. We organized architecture components into two main areas, with a few modules each.
- The world is the area that bridges the app to the environment - it also holds raw data and configurations.
- Application, as you may guess, is the core area.
Below, we show a top-level diagram and briefly list the modules and their responsibility.
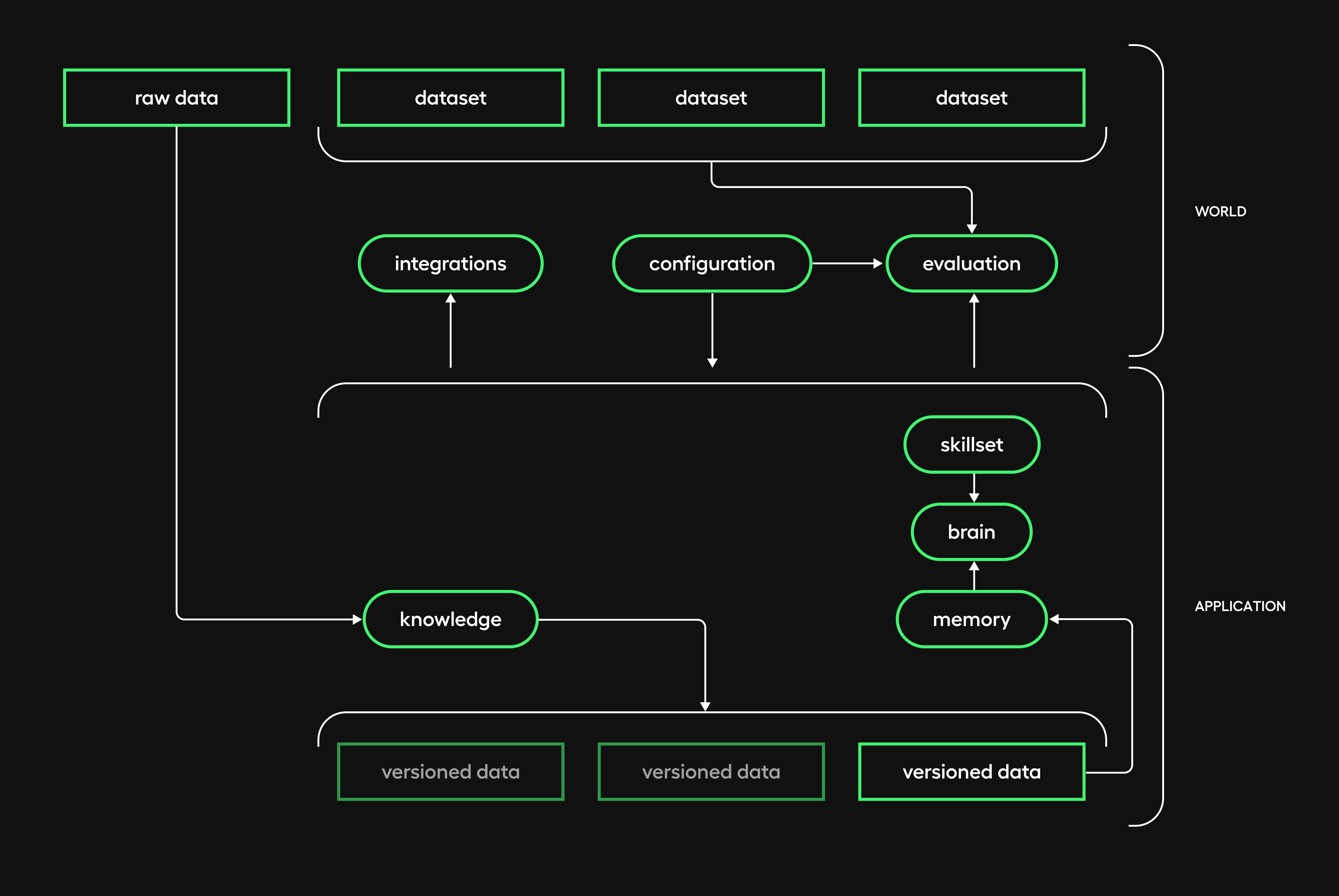
World
Integrations
The main application flow is event-driven. This lets us integrate the app itself into existing tools, as opposed to creating tool integrations into the app. Components that belong to this module are responsible for that integration by connecting Mobegí events and entry points.
As a first implementation, we developed the Slack client.
Evaluation
Components in this module are responsible for automatically monitoring the app-or one of its subsystems-performance over a given dataset, for a given configuration. They are also responsible for creating synthetic datasets.
They don't work at query time at the moment. They may run immediately after ingestion time (when creating datasets), but more generally, they run at their own separate evaluation time.
Feedback collection happens at query time, but it's not considered part of evaluation responsibilities. It is more pure data. When there is enough feedback data, we can use it in the form of a dataset, both for training or evaluating purposes.
Application
Brain
Pipelines and agents are the components that belong to this module.
The main difference is that while the first ones use conventional business logic, the latter ones implement an LLM to develop the logic autonomously.
Nevertheless, both work at query time and are responsible for reasoning and reacting using components from the other modules.
Knowledge
Components in this module work at data ingestion time.
Their primary responsibility is to load, process, transform, and index raw data from the world and create the knowledge base.
Memory
Components in this module work at query time.
Their main responsibility is to retrieve relevant content from the knowledge base and the conversation and provide it as context when processing the following response message.
One of the most interesting challenges was to keep this module decoupled from the knowledge module. We'll go into more detail while describing our configuration approach.
Skillset
Anything can be interpreted as a skill, so the components that belong here provide interaction with the environment or resolve specific needs and work at query time. They are the building blocks for pipelines and agents.
Two things are worth noticing here:
- If a particular subset of skills grows large and important enough, we can separate it into its own module (as we did with memory from the beginning). This is the space where nascent skills can mature until they are robust enough to stand on their own.
- As we will mention in our roadmap chapter, an emergent analogy exists between the initial separation of pipeline steps and agent tools. This overlap will likely lead us to consolidate them into a unified, configurable entity.
Data versioning
With LLMs, data resembles code in traditional software; knowledge comes from curated inputs. So, configurable systems require versioning to select specific data builds.
Imagine testing two document chunking strategies - say, different chunk sizes. Without versioning, we cannot reliably assess the optimal approach. Unversioned, two builds of the same collection become indistinguishable.
Before going into details, let’s clarify the terminology.
- raw data is the source, untreated data
- world data is treated, versioned and stored as a base for
- knowledge data, which is also versioned and indexed and is the data the application is actually using.
The diagram below shows our implementation.
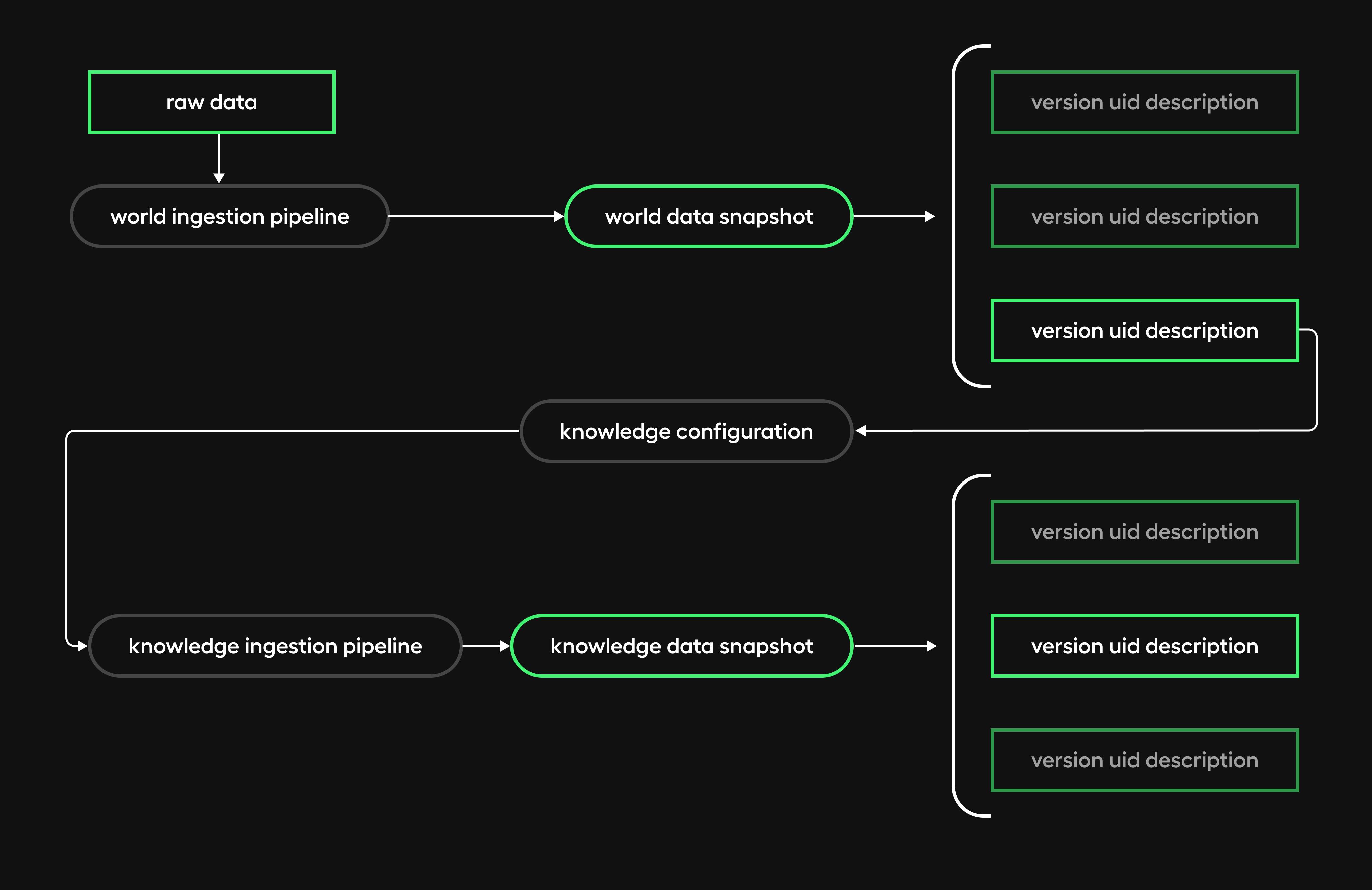
We can use each world version data as the source for one or many knowledge data versions.
The application will then use a particular version of knowledge data, defined in its configuration.
A big inspiration for our implementation has been DVC. Unfortunately, it’s not proper versioning; the collections are copied entirely for each version.
We will give more details while describing the different steps of our ingestion pipeline.
Configuration
The specific knowledge data version gets saved in our configuration file. This configuration file tracks directly to codebase branches for coordinated versioning traceability. By binding configurations to branches, comparing application setups equates to contrasting branches.
The knowledge-memory conundrum
It is worth noting that while a modular design calls for decoupling the knowledge and memory modules, they are unavoidably entangled.
Let's say we index knowledge data using:
- an embedding model
- a chunking mode
- a vectorstore implementation
Retrieval operations rely on consistency with those decisions to query the indexed content accurately. If the retriever in memory attempted to access a collection indexed by a different technique, results would lack relevance or even error entirely. As such, though architecturally distinct, the configuration choices permeate across ingestion and querying - necessitating coordination despite the separation of responsibilities.
Once again, maintaining strict versioning control over data helped with that.
Let’s continue the diagram above, adding one more step at the end of the knowledge ingestion pipeline:
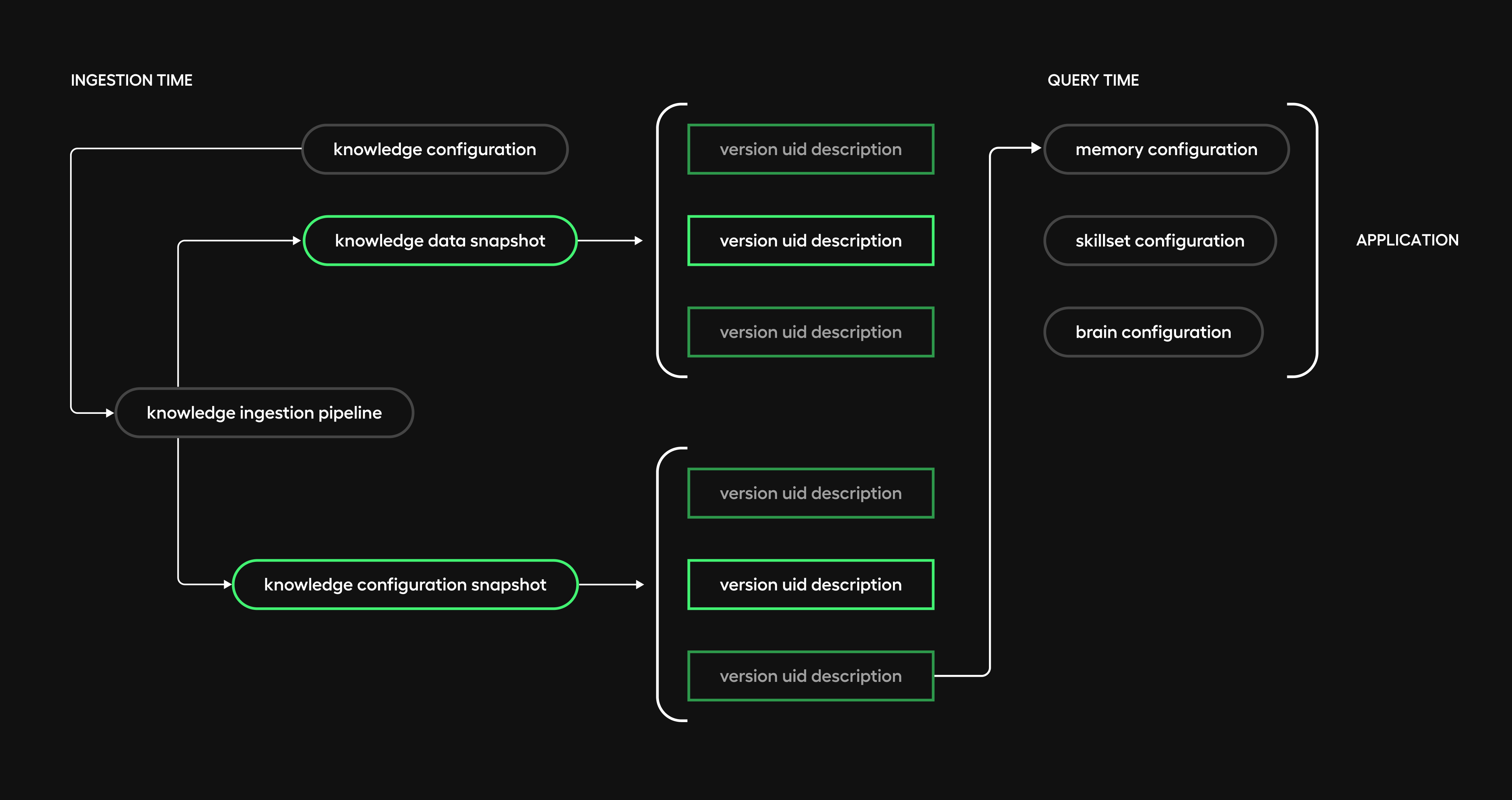
When we create a particular version of knowledge data, we store its version together with
- Its world source version
- The knowledge configuration at creation time
into an object, we called knowledge configuration data snapshot, which is also versioned under the same id as the knowledge data.
This version id is stored as a property in the configuration file.
During bootstrapping, we fetch the snapshot to inject the right knowledge data configuration into memory.
With snapshots as bridges, it doesn’t matter that things like ingestion and retrieval run decoupled. We erase ambiguity between interconnected pipeline pieces by always carrying precise versioning context forward.
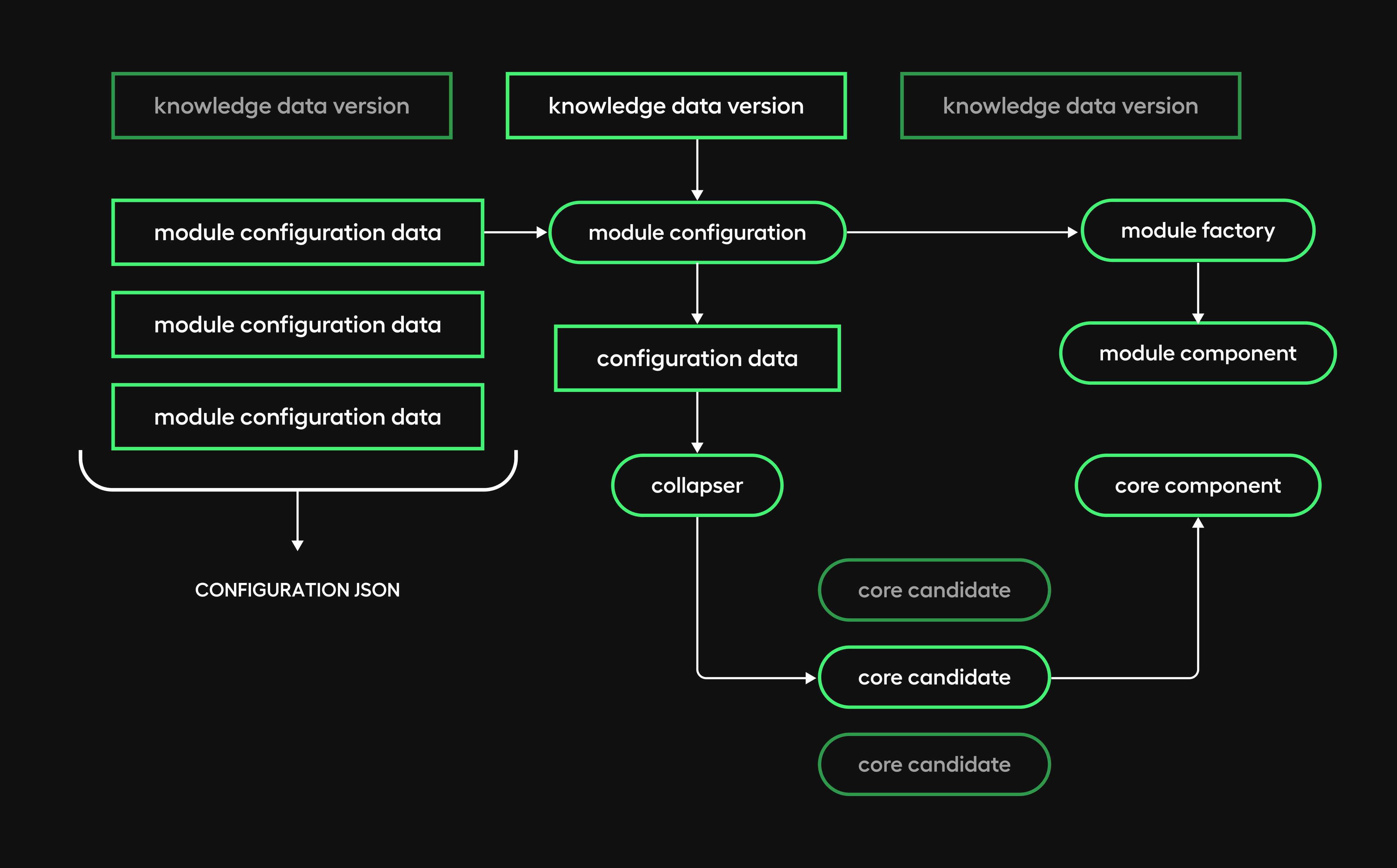
Configuration framework
Configuration data
Several "Core" abstractions, like LLM models, Vectorstores, Embeddings to name a few, are widely used inside all of our modules and have multiple concrete variants that include variant metadata like hyperparameters that get configured at runtime.The main implementation is called mode, the metadata are specific to the implementation. Let’s see Vectorstore configuration data as an example.
class VectorStoreConfigurationData(ConfigurationData[VectorStoreMode]): mode: VectorStoreMode = VectorStoreMode.CHROMA metadata: dict = {
“collection”: DEFAULT_VECTOR_STORE_COLLECTION
}Here mode keeps the main implementation, it’s Chroma, but could be Pinecone, Quadrant, or any other one.
Metadata is a generic dictionary that carries the data we need for that specific implementation – in this case, the name of the collection we are using. During the collapsing phase, we’ll describe shortly, the dictionary will be cast as a specific type. In the example above, this translates into:
class ChromaVectorStoreData(BaseModel): collection: strWe rely on Pydantic to ensure data conformity.
Collapsers
We created specialized components, which we called "Collapsers" to resolve a specific Core variant through configuration data. A collapser is expected to return an interface; when possible, we used base classes and schemas form LangChain as the base return type.
Continuing with the same example, the VectorStoreConfigurationCollapser, receiving our configuration data, will return an instance of a Chroma vectorstore.
It’s interesting to note that in some cases, like the one in the example, the collapser will also need a knowledge configuration data snapshot version, in this case, to point to the right collection.
Configurators
Module-level "Configurators" own all Collapsers required for module assembly, collapsing Cores but retaining an abstract interface.
There are two key points:
- The configurator exposes the collapsers through dictionaries, because inside a module we may need different implementations of the same core abstraction (different LLM models, according to their use).
- When any integrated collapser possesses versioning abilities, they get propagated to the configurator. Upon initialization then, the configurator propagates the version it receives to all the eligible collapsers under its management.
As an example, let’s see the knowledge configurator and how it integrates the vector store collapser.
class KnowledgeConfigurator(ModuleConfigurator[KnowledgeConfigurationData], Versionable):
_vector_store: dict[ConfigurationKeys, VectorStoreConfigurationCollapser]
[...]
def _init_(self, value: KnowledgeConfigurationData):
[...]
self._vector_store = {}
for k, v in value.vector_store.items():
self._vector_store[k] = VectorStoreConfigurationCollapser(
value=v, embeddings=self._embeddings[k].implementation()
)
[...]
@version.setter
def version(self, value):
for v in self._vector_store.values():
v.version = value
self._version = value
def vector_store(self, key: str, **kwargs) -> VectorStore:
return self._vector_store[key].implementation(**kwargs)
[...]Factories
Finally, module-level factories are constructed, injecting the corresponding module configurator, plus all the other dependencies needed to build module components.
As an example, let’s take the knowledge factory:
class KnowledgeFactory:
_configurator: KnowledgeConfigurator
[...]
def ingest_knowledge_pages_collection(self) -> IngestData[Page, VectorStore]:
return IngestKnowledgePagesCollection(self._configurator.vector_store(ConfigurationKeys.PAGES.value))
[...]The diagram below explains the whole configuration process visually:
Coming next
Thanks for following along to understand Mobegí’s core foundations! We discussed the modular architecture and configuration infrastructure to enable evaluation and adaptability over time.
If you’re intrigued to see more, we invite you to join us in exploring Mobegí’s data ingestion pipeline next.