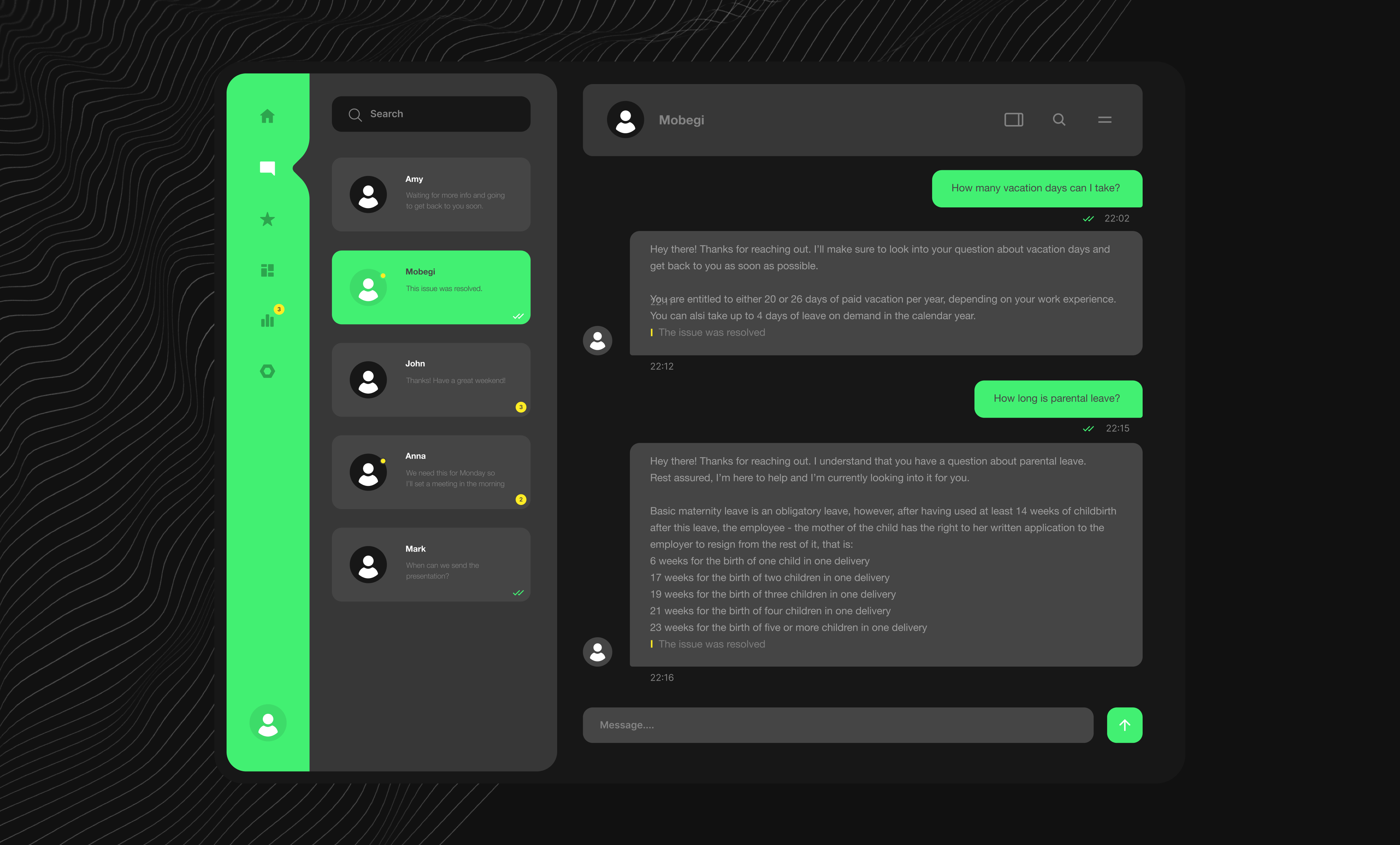
Welcome to our exciting blog series, where we delve into the creation of our internal AI-powered tool designed to revolutionize access to internal documentation. Our journey began when the office operations team recognized the need for a more efficient way to navigate and utilize our extensive internal resources. This led to the birth of Mobegí, a name inspired by the Esperanto phrase for "set in motion." It perfectly encapsulates the essence of our tool – propelling user queries toward effective and actionable answers.
In this six-part series, we invite you to join us on an enlightening adventure through the rapidly evolving landscape of Generative AI, the technology at the heart of Mobegí. Each post will offer valuable takeaways – we'll reveal the challenges we faced, the solutions we discovered, and the knowledge we gained while building the app. You’ll find there examples of code, logic behind main features, diagrams, and useful links. Moreover, we'll glimpse what the future holds for AI in the information access and management sector.
So, whether you're a tech enthusiast, an AI expert, or simply someone curious about the practical applications of cutting-edge technology, this series will be an enriching journey full of insights and innovations. Join us in the first part, where we'll explore the idea behind Mobegí, and stay tuned for the following chapters!

About
The office operations team had become the de facto entry point for employee questions or information requests. Their availability made employees rarely venture to search independently for answers, even despite the existence of detailed documentation.
With all inquiries funneled to the operations team, staff spent the majority of time locked into handling repetitive requests for general information. This prevented them from focusing on more strategic, value-add responsibilities that leveraged their expertise. It also led to longer response times, delaying employee access to timely knowledge.
We considered leveraging AI to automate the handling of frequent requests at scale, freeing staff focus. Specifically, we explored modern language model capabilities for deep comprehension of questions and relevant knowledge passages. Retrieval-augmented generation (RAG) showed particular promise. By first retrieving related evidence and then generating responses conditioned on that contextual evidence, RAG offered an ability to respond to repetitive questions while capturing nuances within company documentation.
We saw an opportunity to make company knowledge access more approachable by providing a conversational interface through a Slack dedicated bot and overcoming employee reluctance to dig through documentation for answers.
That said, we never aimed for pure self-service but rather for optimal assignment between bot-assisted responses and human expertise. By providing a natural channel for queries, both repetitive requests and more complex questions could be fielded to the right resources –either automated responses drawing from a knowledge base or routed to the operations staff with full context from the conversation history.
Our generative AI solution, Mobegí, is a RAG-based LLM application based on Apptension Confluence Internal space documentation.
The system components are based on Python 3.10.12.
Our main dependencies are:
- Pydantic, a powerful Python library for defining data structures and ensuring data conformity to those structures. It is also used for validating and deserializing JSON data.
- Natural Language Toolkit, a leading platform for building Python programs to work with human language data. In particular, we leveraged its sentence tokenizer.
When the components are LLM-based, they are implemented through LangChain 0.0.312 and its Expression Language declarative syntax (more details are provided in the stack section).
It is worth mentioning that at the time of writing, LangChain announced a re-architecture of the package into multiple packages.
The application is currently delivered through a Slack app, but the separation of concerns allows client flexibility.
The word Mobegí sounds like “set in motion” in Esperanto; we found it a perfect fit for the product. It sets in motion the query, retrieves relevant information in the documentation, and uses it to provide an answer to be validated by the office team.
First thoughts
After the experience with our first prototype, we realized a few things:
- Refined data treatment is crucial.
- Raw inputs frequently contain noise, redundancy and contradictions.
- Securing data risks further inaccuracies – masking techniques like perturbation can severely impact output quality.
- With clean, relevant knowledge, retrieval becomes far simpler.
- Data versioning emerged as a challenging pending task.
- Evaluation requires a solid framework for systematic, configurable testing of the overall application or any modular component.
We intended this project to be a sandbox – not just for gathering Generative AI knowledge but also for rehearsing real-world complexities to come.
We emphasized areas that are easy to deprioritize in prototypes, like data ingestion, evaluative coverage, maintainability, and data ownership.
Lastly, after a soft release to our office team, we engaged them as pseudo-clients – consultative benefactors granting consumer insights from within.
Allowing their feedback cycles to redirect workflow, we focused on pertinent complexities revealed through our cooperation.
What is RAG, by the way?
You may be familiar with the following concepts. If you feel they are redundant, please feel free to proceed to the stack section.
RAG
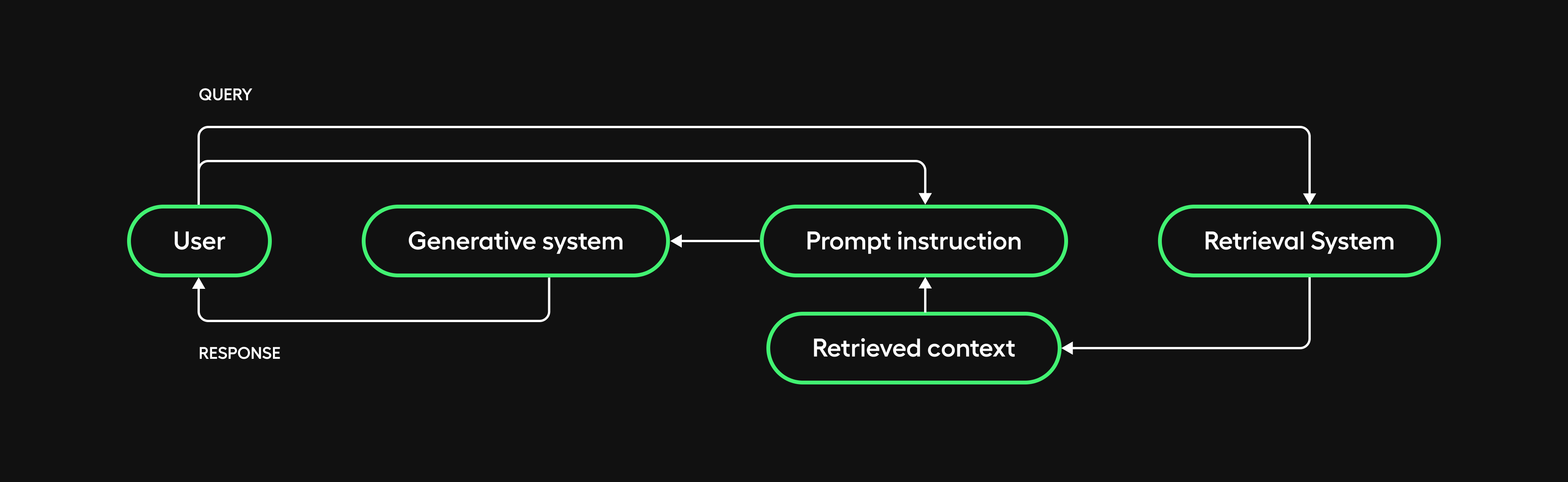
It stands for Retrieval-Augmented Generation. As the name suggests, a RAG system merges both an information retrieval and a generative subsystem.
On the retrieval end, relevant data is pulled from a knowledge base or set of documents based on a given query or context, using techniques like information retrieval or semantic search. Then, the generative component, which couldn’t on its own have access to custom knowledge, makes sense of the retrieved materials to construct the final responses.
This combined architecture plays to the strengths of both retrieval and generation to overcome their individual limitations.
Vectorstore
A particular type of dense vector retrieval system, which leverages embeddings to encode texts – or more generally unstructured data – into vector representations.
By encoding text into embedding spaces, a vectorstore facilitates efficient semantic similarity search even across large corpora.
When a user query is mapped into the embedding vector space, similarity search algorithms can rapidly compare it to the vectors encoded in the vectorstore to identify the passages with the most similar representations.
Embeddings
The mathematical mapping of discrete data fragments into a continuous vector space. The position of the embedding vector encodes aspects of meaning based on proximity to other related vectors.
They are generated by training machine learning models - like Word2Vec or BERT in NLP – on large corpora to build vector representations reflecting real-world usage and patterns.
The key advantage of embeddings is enabling semantically-aware analogical operations.
Context window
The information that a generative conversational AI model can access when formulating its next response. The size of this window is constrained by the model's maximum token capacity. Tokens refer to the embedded vocabulary units that serve as the atomic building blocks for sequences in natural language models. A model with a 32,000 token size, for example, can process up to 32,000 tokens split between the conversational context it's shown and the response it will generate.
Engineering an optimal context window is crucial but challenging in striking the right relevance-conciseness balance. Models suffer substantial performance degradation – a phenomenon referred to as "lost in the middle" – when retrieving over 10 lengthy documents, for instance. They tend to ignore information embedded in the middle of such very long contexts.
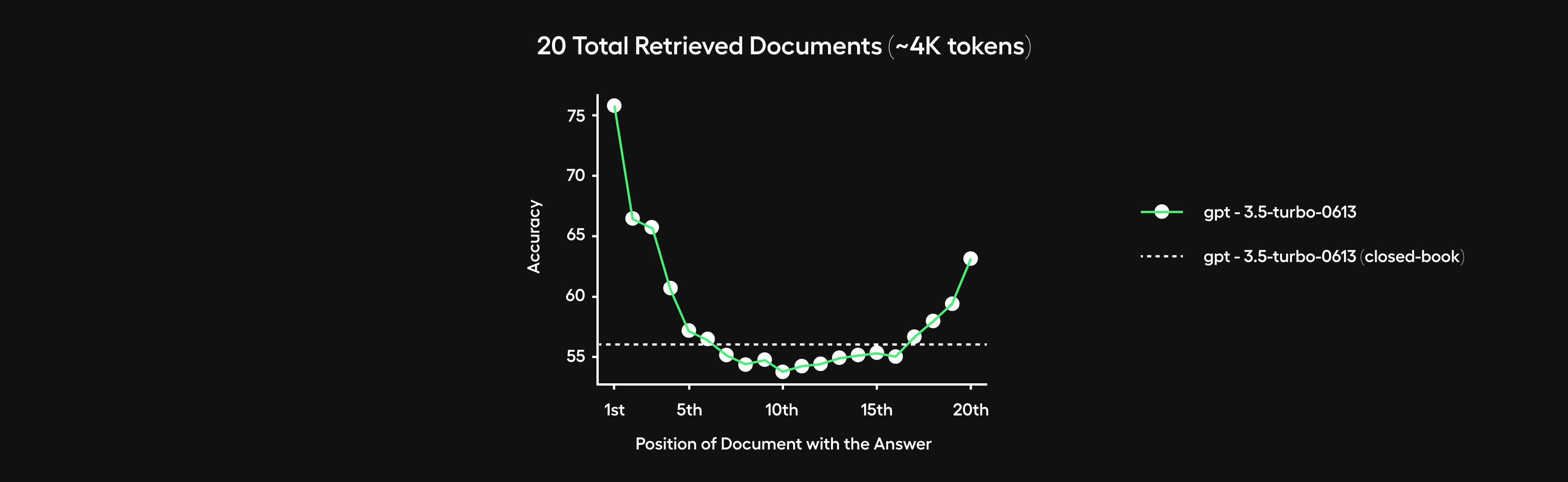
However, over-compressing conversational context runs the risk of eliminating relevant information from earlier in the exchange. While compacting exchanges aids in quickly catching up on recent messages, retaining critical specifics mentioned previously could still prove useful for crafting maximally informed responses. There are likely complex tradeoffs around context compression – sufficiency versus brevity.
Semantic Compression With Large Language Models is an interesting paper covering the topic and proposing metrics to evaluate reconstruction effectiveness.
The stack
Firestore
We chose Firestore since our team already had strong experience with it from previous projects. With substantial unfamiliar tech across emergent AI domains, reducing platform complexity was helpful. Firestore also came at basically no cost given our experimental stage, which is another plus when exploring uncertain terrain.
LangChain
Adopting LangChain's framework inherently meant some additional abstraction. However, several clear advantages emerged – particularly around focusing engineering on prompts and solutions without reinventing lower-level capabilities.
Importantly, LangChain benefits from a vibrant open-source community. This collaborative ecosystem likely fueled their rapid delivery pace.
You can learn more about LangChain here.
When in July 2023 they launched Langsmith, and a few months after their Expression Language, we knew we had made the right choice.
To be fully transparent, reading about LangChain launching tools parallel to our own development often proved frustrating. Yet it equally validated we worked on the right problems. After all, our independent ideas aligned closely with what their community designer chose as well.
In a fast-moving ecosystem, some duplication of effort is inevitable. However, shared priorities like theirs demonstrated that we identified meaningful gaps in the existing space.
Langsmith
Langsmith serves as LangChain’s debug and experimentation suite. We initially integrated it solely for its granular debugging visibility – tracing runtime data and decisions across chained model requests identifies failure points or data drift issues.
Eventually, we expanded Langsmith’s role to facilitate critical activities like benchmarking variants and comparing outputs.The combination of observability into model behaviors and an integrated workspace to conduct prototyping analyses made Langsmith an invaluable asset as our evaluation needs grew.
At the moment of writing, they are in closed beta. You can request access here.
Expression Language (LCEL)
It’s a syntax they introduced in August 2023 to create chains with composition. It came along with a new common interface that supported batch, async, and streaming out of the box. In addition to that, it made it easier for users to customize parts of the chains and integrate seamlessly with LangSmith.
If you want to learn more, this is a good starting point.
Chroma
After testing Pinecone in our previous prototype, this was probably the area where we had the widest range of possibilities. This article provides a comparison and a holistic view of most of them. Eventually, Chroma appeared as a valid alternative.
While nascent, their visionary designs and our alignment on problem perspectives made Chroma a promising vector store. Alternative hosting architectures and computational backends remain under exploration as well.
You can learn more about Chroma here:
- https://www.trychroma.com/
- https://docs.trychroma.com/usage-guide?lang=py
- https://docs.trychroma.com/getting-started
Slack
We selected Slack to avoid dedicating resources to a custom user interface during these exploratory stages. Additionally, it was an opportunity to validate our capability to integrate the app with existing tools.
Slack specifically offered internal visibility for wider evaluation. Rather than siloed experiments, publishing within shared channels lets cross-functional teams experience and critique results firsthand.

A note about knowledge graph dbs
A knowledge graph, also known as a semantic network, represents a network of real-world entities –i.e. objects, events, situations, or concepts –and illustrates their relationship.
During the initial phases of our LLM app development, we tested:
- Neo4j – a proprietary solution with extensive documentation and a learning platform.
- Kuzu: – an open source alternative with good support in LangChain.
The adoption of knowledge graphs was woven into an agentic approach designed for our QA pipeline. However, as we pivoted away from this approach, the primary purpose of the knowledge graph diminished despite the promising outcomes from our initial experiments.
Taking a step back, it seems that diving into both topics might have been a tad premature during those early stages. That said, it is something we may reconsider in the near future and with the expertise we gathered in the meantime.
Coming next
Thank you for reading this deep dive into Mobegí's beginnings! We covered the needs behind automating office assistance, key terminology like RAG systems, takeaways from initial prototyping, and the technology stack powering our solution.
If you're interested, in the next chapter, we'll explore Mobegí's modular infrastructure and configuration. This architecture is crucial for enabling flexible orchestration and upgrades at scale.